




![]()
In this blog, we are going to discuss the Importance and usage of DevOps for Data Science. we are going to discuss terms like:
- What is DevOps?
- What are the Fundamentals Of DevOps?
- DevOps Lifecycle
- What is Data Science?
- Data Science Lifecycle
- Why do Data Scientists and DevOps need to know about Each Other?
- How does DevOps support the deployment of data models?
- What is MLOps?
- Is DataOps the DevOps of the Future? How does MLOps feature in this narrative?
- DevOps vs Data science – how these work or give benefits.
- Conclusion.
Now, Let’s see what is DevOps and how DevOps and Data Science is Correlating in today’s world…
What is DevOps?
DevOps is a set of practices that combines software development (Dev) and IT operations (Ops). It aims to shorten the systems development life cycle and provide continuous delivery with high software quality. DevOps is complementary to Agile software development.
DevOps is the union of people, processes, and technology to continually provide value to customers.
What are the Fundamentals Of DevOps?
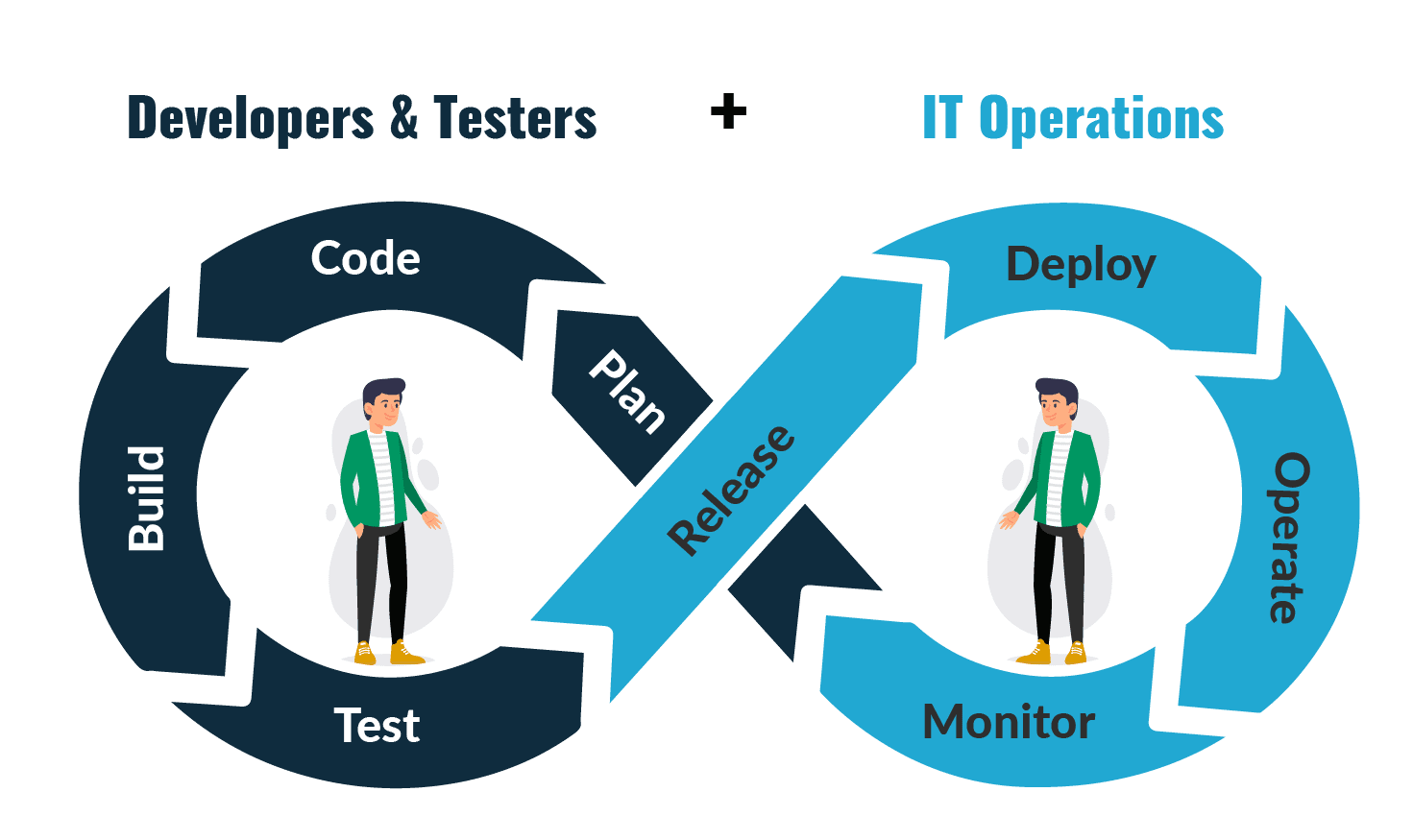
- Code: The first step in the DevOps life cycle is coding, where developers build the code on any platform
- Build: Developers build the version of their program in any extension depending upon the language they are using
- Test: For DevOps to be successful, the testing process must be automated using any automation tool like Selenium
- Release: A process for managing, planning, scheduling, and controlling the build in different environments after testing and before deployment
- Deploy: This phase gets all artifacts/code files of the application ready and deploys/executes them on the server
- Operate: The application is run after its deployment, where clients use it in real-world scenarios
- Monitor: This phase helps in providing crucial information that basically helps ensure service uptime and optimal performance
- Plan: The planning stage gathers information from the monitoring stage and, as per feedback, implements the changes for better performance
Check Out: Data Science Interview Questions.
DevOps Lifecycle
Now, let’s discuss the different stages in the DevOps Data Science lifecycle that contributes to the consistent software development life cycle (SDLC):
- Continuous Development
- Continuous Integration
- Continuous Testing
- Continuous Monitoring
- Virtualization and Containerization
These stages are basically the aspects for achieving the DevOps goal
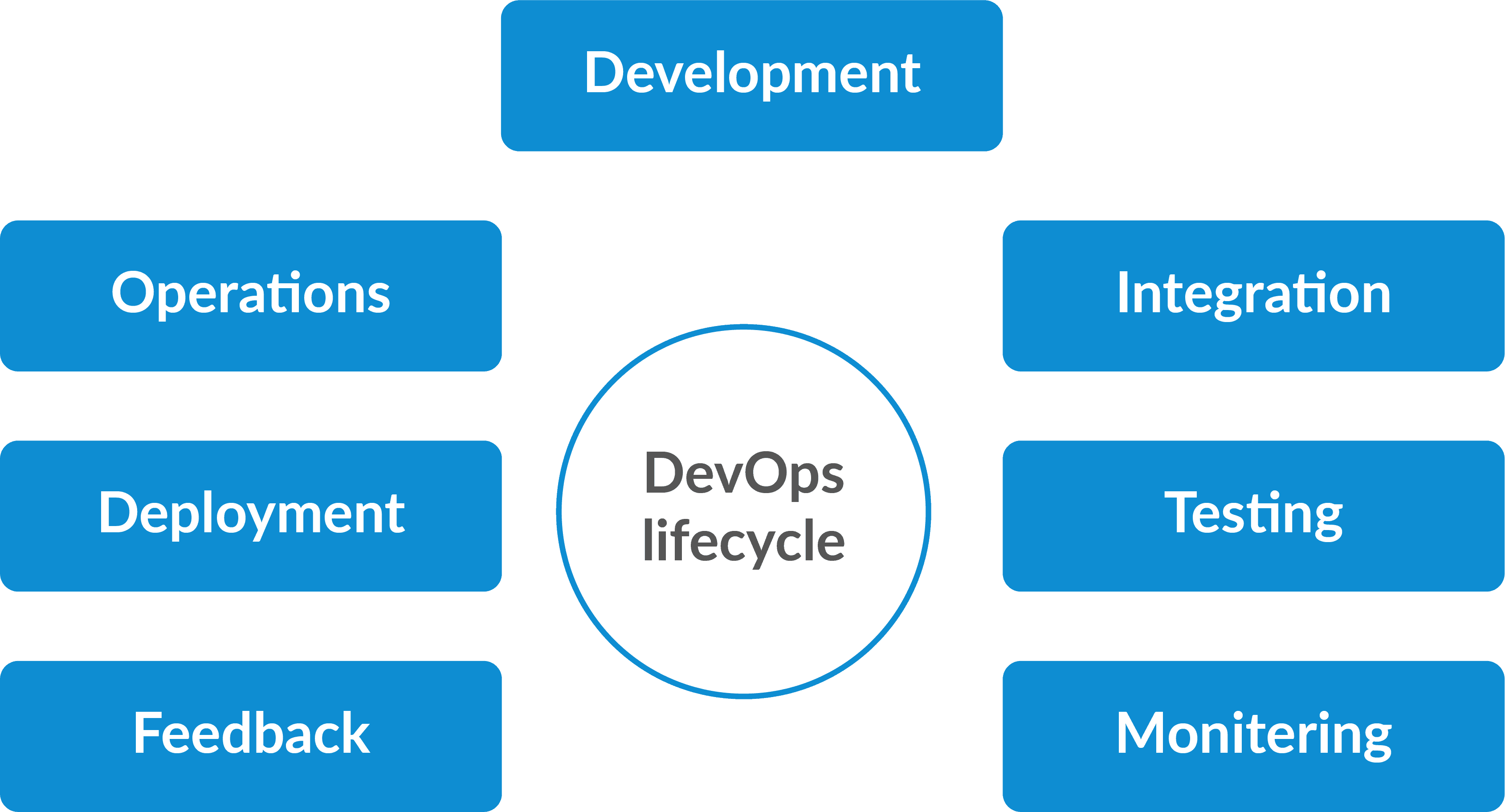
Now, let’s discuss each of them in detail.
Continuous Development
In the Waterfall model, our software product gets broken into multiple pieces or sub-parts for making the development cycles shorter, but in this stage of DevOps data science , the software is getting developed continuously.
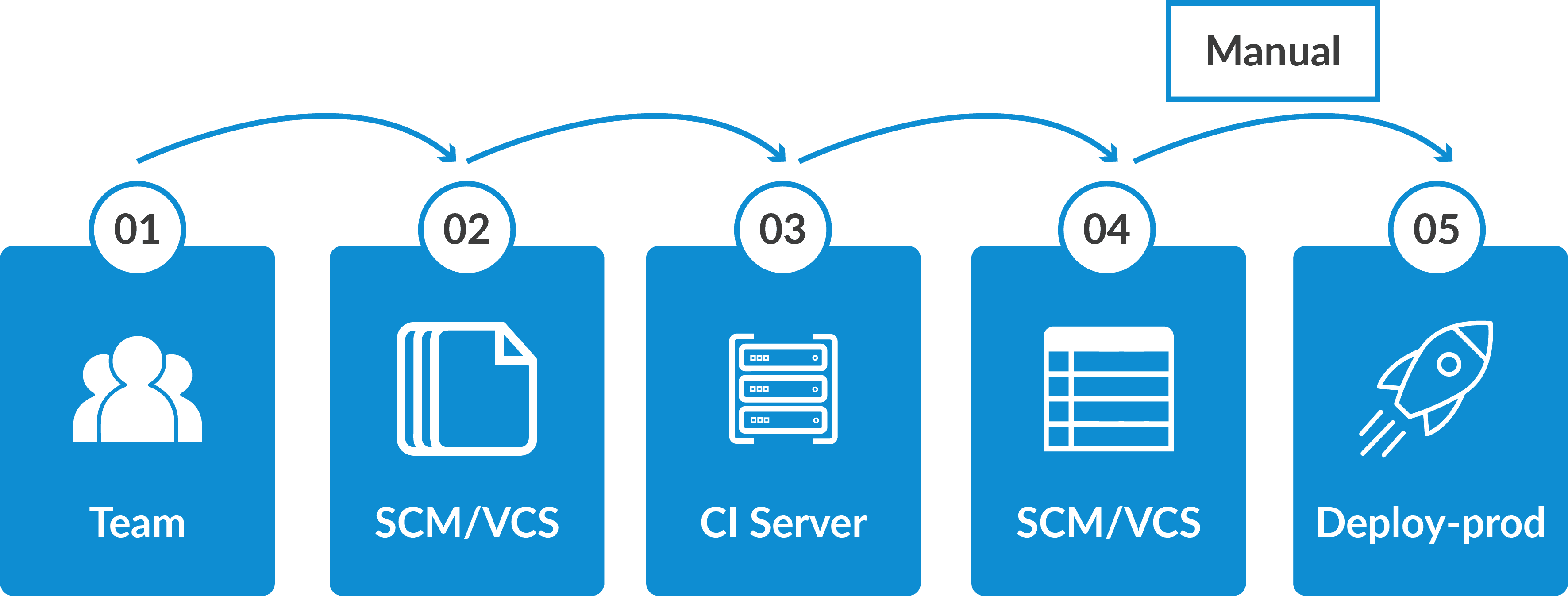
- Tools used: As we code and build in this stage, we can use GIT to maintain different versions of the code. To build/package the code into an executable file, we can use a reliable tool, namely, Maven.
Continuous Integration
In this stage, if our code is supporting new functionality, it is integrated with the existing code continuously. As the continuous development keeps on, the existing code needs to be integrated with the latest one ‘continuously’, and the changed code should ensure that there are no errors in the current environment for it to work smoothly.
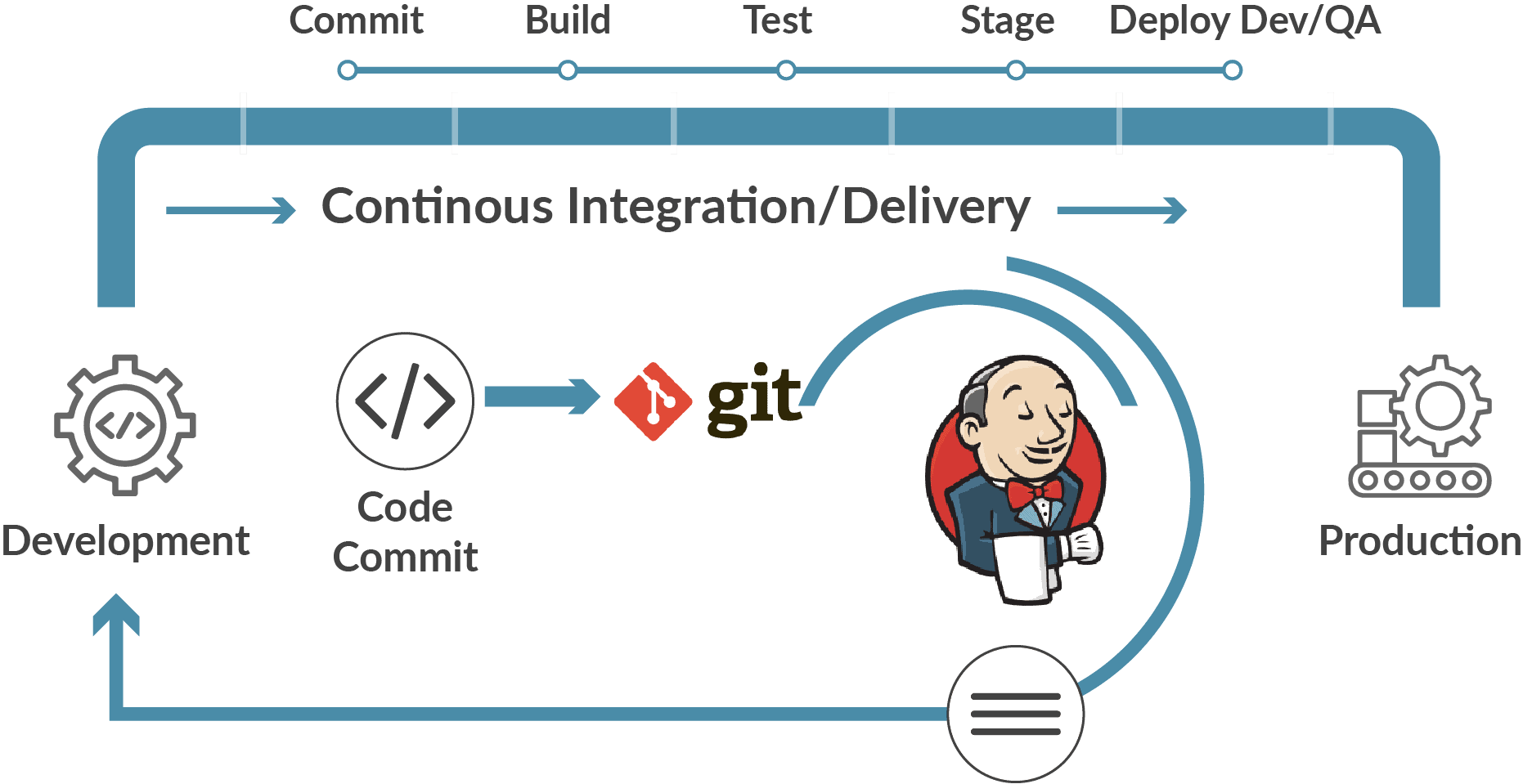
- Tools used: Jenkins is the tool that is used for continuous integration. Here, we can pull the latest code from the GIT repository, of which we can produce the build and deploy it on the test or the production server.
Continuous Testing
In the continuous testing stage, our developed software is getting tested continuously to detect bugs using several automation tools.
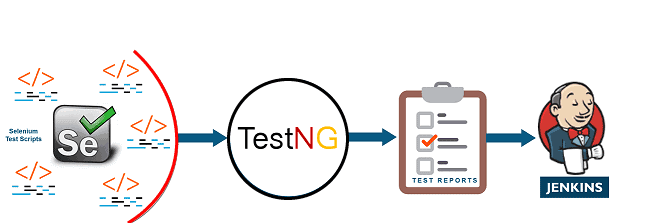
- Tools used: For the QA/Testing purpose, we can use many automated tools, and the tool used widely for automation testing is Selenium as it lets QAs test the codes in parallel to ensure that there is no error, incompetencies, or flaws in the software.
Continuous Monitoring
It is a very crucial part of the DevOps life cycle where it provides important information that helps us ensure service uptime and optimal performance. The operations team gets results from reliable monitoring tools to detect and fix the bugs/flaws in the application.
- Tools used: Several tools such as Nagios, Splunk, ELK Stack, and Sensu are used for monitoring the application. They help us monitor our applications and servers closely to check their health and whether they are operating actively. Any major issue detected by these tools is forwarded to the development team to fix in the continuous development phase.
What is Data Science?
- Data Science is a discipline relying on data availability, while business analytics does not completely rely on data.
- Data Science covers part of data analytics, particularly that part which uses programming, complex mathematical, and statistical. it is not completely overlapping Data Analytics but it will reach a point beyond the area of business analytics.
- It can be used to improve the accuracy of prediction based on data extracted from various activities.
- Business intelligence fits in data science because it is the preliminary step of predictive analytics because we first analyze past data and extract useful insights and then create appropriate models that could predict the future of ours business accurately.
Data Science Lifecycle
Data Science Devops Lifecycle revolves around the use of machine learning and different analytical strategies to produce insights and predictions from information in order to acquire a commercial enterprise objective. The complete method includes a number of steps like data cleaning, preparation, modelling, model evaluation, etc. It is a lengthy procedure and may additionally take quite a few months to complete. So, it is very essential to have a generic structure to observe for each and every hassle at hand.

Data Science Lifecycle |
|
|---|---|
| 1. Business Understanding |
|
| 2. Data Understanding |
|
| 3. Preparation of Data |
|
| 4. Exploratory Data Analysis |
|
| 5. Data Modeling |
|
| 6. Model Evaluation |
|
| 7. Model Deployment |
|
What is the role of Infrastructure as Code (laC) in data services?
Infrastructure as Code (IaC) plays a crucial role in data services by automating the provisioning, management, and scaling of infrastructure. It ensures consistency, enhances efficiency, and simplifies deployments, enabling seamless integration of data pipelines and services across environments.
What are the methods for performing unit and integration testing for data transformation and processing?
Unit testing for data transformation involves testing individual functions or components with controlled inputs and expected outputs, ensuring accuracy. Integration testing verifies the end-to-end flow of data processing pipelines, validating seamless integration, correctness, and performance across systems.
What are the roles and responsibilities of data engineers in data pipelines?
Data engineers design, build, and maintain data pipelines to ensure seamless data flow between systems. Their responsibilities include data extraction, transformation, and loading (ETL), ensuring data quality, optimizing performance, and enabling scalable, reliable data infrastructure for analytics and machine learning.
How can automated security measures and compliance checks be integrated into CI/CD pipelines?
Automated security measures and compliance checks can be integrated into CI/CD pipelines by embedding tools for static code analysis, vulnerability scanning, and compliance validation at each stage, ensuring continuous monitoring, early detection, and remediation of security risks during development and deployment.
Why do Data Scientists and DevOps need to know about Each Other?
- Data scientists create value by experiments: new ways of modelling, combining, and transforming data. Meanwhile, the organizations that employ data scientists are incentivized for stability.
- Data scientists and the developers and engineers who implement their work have entirely different tools, constraints, and skillsets. DevOps emerged to combat this sort of deadlock in software, back when it was developers vs. operations.
- The DevOps community states that organizations need to break down this wall of confusion between Development (Dev) and Operations (Ops). We see this ‘wall of confusion’ applies in the data science world as well. Data Scientists mainly focus on developing advanced analytics models. Bringing advanced analytic models to ‘production’ and operating a model running in production is not part of their formal role in the organization. As stated earlier, the skills for both of these activities are also limited for the average Data Scientist.
- The DevOps Agile Skills Association (DASA) defined 6 principles, which should be adopted by an organization that wants to adopt DevOps. These principles are depicted in the below image.
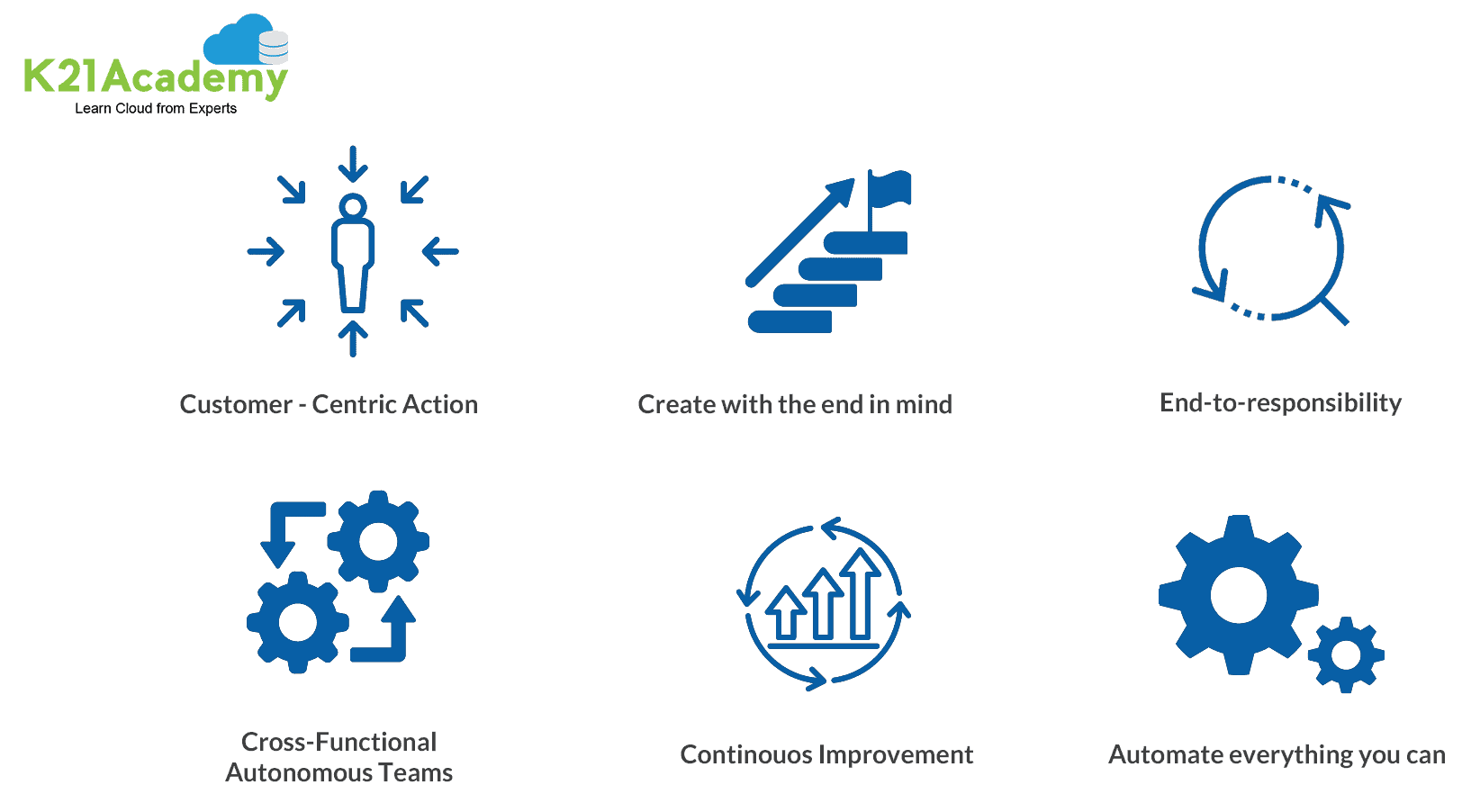
An organization that adopts these 6 principles will deliver business value faster, etc. For our use case: breaking down the wall of confusion between Data Science and Operations of Data Applications in an enterprise setting, principles 3 and 4 are most important. The details will be discussed later. First, the details of both worlds in practice are discussed.
| Bridging the knowledge gap in the deployment process |
|
|---|---|
| Infrastructure Provisioning |
|
| Iterative Developments |
|
| Scalability |
|
| Monitoring |
|
| Containerization |
|
How does DevOps support the deployment of data models?
Different types of data models require dedicated production infrastructure that can support the operation of individual data models. Such niche requirements create confusion and ultimately trigger major hindrances during project implementation.
However, in the same way, that segregation between software engineering and DevOps engineering hinders smooth workflows, the absence of a cohesive collaboration between data scientists and DevOps engineers deters smooth operational processes as well. And the functions of the DevOps engineers can quite easily be embraced by data science teams.
Being a part of the DevOps process does not mean that one needs to be a DevOps engineer. It simply means that when working on DevOps:
- All Python model codes need to be committed to a repository, and all and any changes to existing model codes need to be managed through the existing repository.
- Codes need to be integrated with Azure ML via Software Develop kits so that all changes, feature alterations can be logged and tracked for later referencing.
- Given that the DevOps process is automated to build and create codes and artifacts, ensure that you do not manually release or build your code or artifacts to any location other than your experimenting ground
With these few, simple steps, data science teams and DevOps teams can easily collaborate with one another. Some data scientists might not be well-versed with using versioning tools such as Git and might take time to implement continuous delivery and deployment setups.
How can lac be used to deploy data services within a secure network configuration?
Infrastructure as Code (IaC) automates the deployment of data services within a secure network by defining configurations in code. This ensures consistent setups, integrates security policies like firewalls and encryption, and simplifies provisioning within protected environments.
What are the steps involved in deploying data factory changes automatically using CI/CD?
What is MLOps?
MLOps or Machine Learning Operations is based on DevOps principles and practices that increase the efficiency of workflows and improves the quality and consistency of the machine learning solutions.
MLOps = ML + DEV + OPS
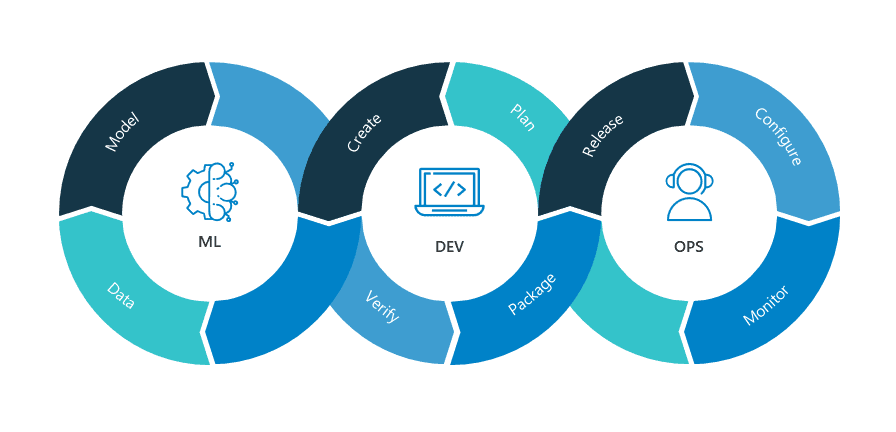
MLOps is a Machine Learning engineering culture and practice that aims at unifying ML system development (Dev) and ML system operation (Ops). It applies the DevOps principles and practices like continuous integration, delivery, and deployment to the machine learning process, with an aim for faster experimentation, development, and deployment of Azure machine learning models into production and quality assurance.
Is DataOps the DevOps of the Future? How does MLOps feature in this narrative?
DevOps signalled a sea of change with its inception and a truly efficient DevOps process can reduce delivery time from months to mere days. However, many believe that another upcoming technology has the potential to be the next big thing – Data Ops. In 2018, about 73% of companies were reportedly investing in DataOps.
- Simply put, we could consider that Agile + DevOps + lean manufacturing = DataOps.
- Once the development phase of DataOps is completed, CI can be setup to maintain the quality of the code on the master branch. At the end of each sprint, developers will merge all their changes into the master branch, where all the test cases are run before the branch is accepted.
- This step is then followed by identifying the CD pipeline that can be run to generate artifacts of models, which can then be stored on the cloud. As part of the deployment process, at the end of each sprint, dockerizing, i.e., converting a software application to run within a specified docker, is undertaken.
Here is an overview of the three aforementioned technologies – and their characteristic features.
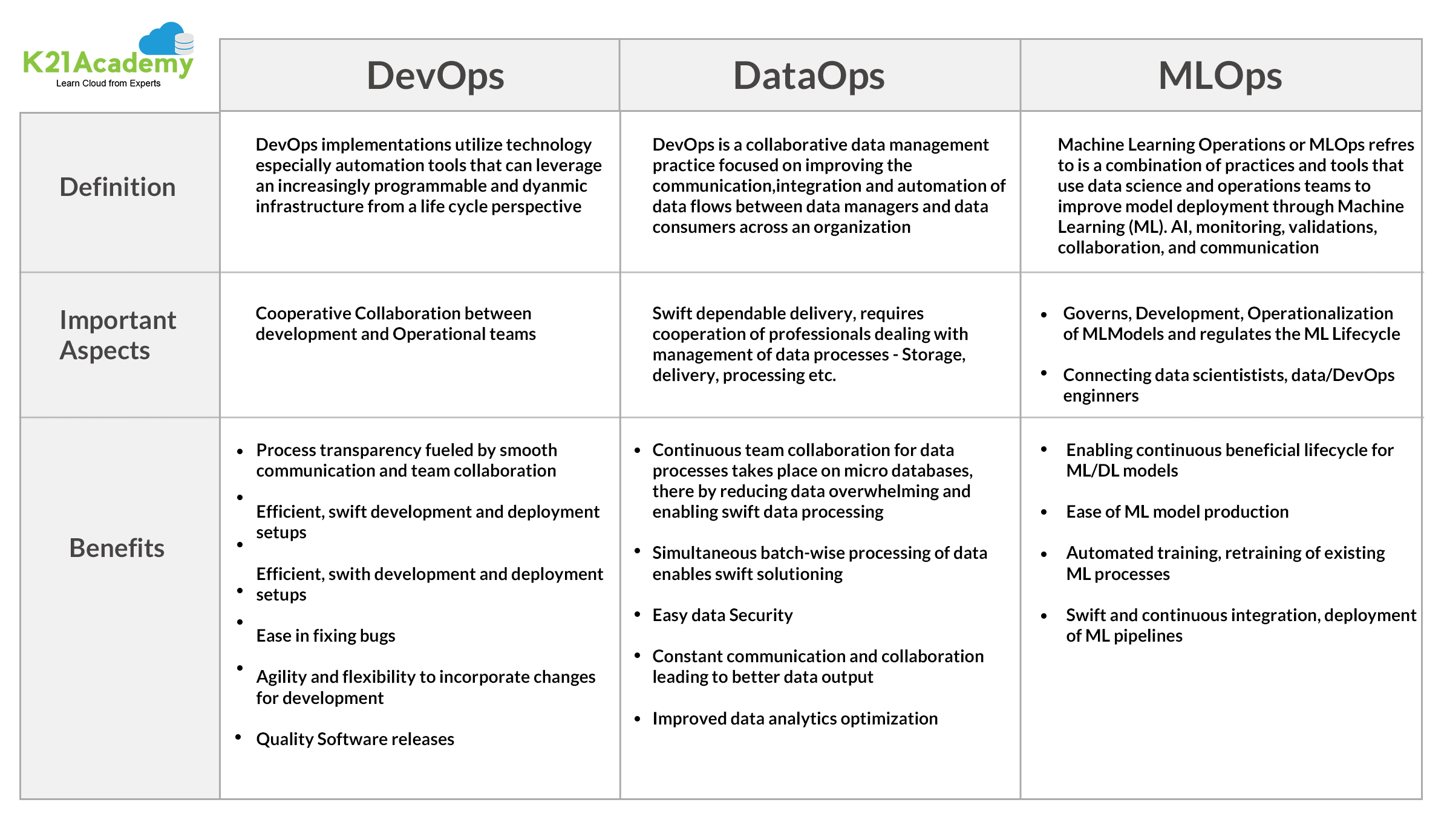
Overall, some believe that merging the two practices of DevOps and DataOps would qualify as a ‘match made in heaven’, others are still skeptical about the coupling and believe that the match is incomplete without the inclusion of MLOps. Some articles point out that there are ‘too many Ops’. Perhaps, given that DevOps setups have been around for more than a decade and DataOps is still in the nascent stages of application. MLOps too is, in a sense, in its infancy. Companies might hesitate to adopt MLOps as there are no universal guiding principles yet, but what we need is a leap of faith to ensure that we get started with the implementation process in order to stay ahead of the curve.
DevOps vs Data science – how these work or give benefits.
Developers have their own chain of command (i.e. project managers) who want to get features out for their products as soon as possible. For data scientists, this would mean changing model structure and variables. They couldn’t care less what happens to the machinery. Smoke coming out of a data centre? As long as they get their data to finish the end product, they couldn’t care less. On the other end of the spectrum is IT. Their job is to ensure that all the servers, networks, and pretty firewall rules are maintained. Cybersecurity is also a huge concern for them. They couldn’t care less about the company’s clients, as long as the machines are working perfectly. DevOps is the middleman between developers and IT.
Some common DevOps functionalities involve:
- Integration: continuous integration tools, build status.
- Testing: continuous testing tools that provide quick and timely feedback on business risks.
- Packaging: artefact repository, application pre-deployment staging.
- Deployment: code development and review, source code management tools, code merging.
DevOps Phases
Conclusion.
The isolated lab setting that many organizations have for their data science capability needs to be replaced by a professional Data & Analytics domain in combination with mature business and product teams that adopt the Data Science capabilities. The Data & Analytics domain will provide user-friendly self-service services for Data & Insights consumption and creation. This way Data Scientists are facilitated and can take end-to-end responsibility for their models
Related/References
- Join Our Generative AI Whatsapp Community
- Azure AI/ML Certifications: Everything You Need to Know
- Azure GenAI/ML : Step-by-Step Activity Guide (Hands-on Lab) & Project Work
- DP 100 Exam | Microsoft Certified Azure Data Scientist Associate
- [DOFD] DevOps Foundation Certification Exam: Everything You Need To Know
- CI/CD Pipeline | Continuous Integration | Continuous Deployment
- What Is DevOps?
- Introduction To Data Science and Machine Learning
Next Task: Enhance Your Azure AI/ML Skills

![Microsoft Agentic AI Business Solutions Architect [AB-100] | K21 Academy](https://test.k21academy.com/wp-content/uploads/2025/11/Microsoft-Agentic-AI-Business-Solutions-Architect-AB-100-Exam-Overview1.png)



