



![]()
In this blog, we are going to cover the Importance and use of DevOps Architecture in Data Engineering (DataOps) & Dataops vs Devops.
Topics, we’ll cover:
What is DevOps? | DevOps Lifecycle | What is Data Engineering? | What is DataOps? | Difference between DevOps vs DataOps | Why DataOps for Data-Engineering? | How DataOps is used in azure? | What are the benefits of DataOps? | Conclusion.
What Is DevOps?
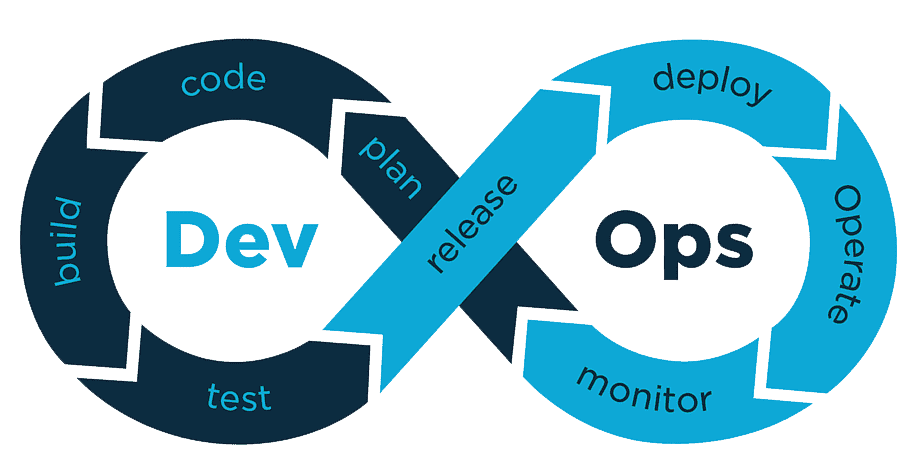
- DevOps is the combination of development (Dev) and IT operations (Ops). It is that the union of individuals, processes, and technology to repeatedly provide value to customers.
- DevOps breaks down the wall between Operations and Engineering by cross-training each team within the other’s skills. This leads to higher quality collaboration and more frequent communication.
DevOps Lifecycle

Devops consists of various stages/phases such as Continuous Development, Continuous Integration, Continuous Testing, Continuous Deployment, Continuous Monitoring constitutes Devops lifecycle. We will discuss each phase of the DevOps life cycle one by one.
1) Continues Development
This phase involves 2 things ‘planning ‘and ‘coding ‘of the software. The vision of the project is set during the design phase and therefore the developers begin developing the code for the appliance. There are not any DevOps tools that are required for planning, but there are a variety of tools for maintaining the code.
The code is maintained by using Version Control tools. Maintaining the code is mentioned as ASCII text file Management. The tools that will be used are Git, SVN, Mercurial, CVS, and JIRA. Also, tools like Ant, Maven, Gradle have often been utilized in this phase for building/ packaging the code into an executable file which will be forwarded to any of the Further phases.
Also Read: Our blog post on Azure Data Engineer Interview Questions.
2) Continuous Testing
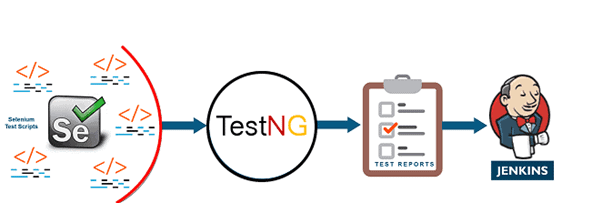
After the successful completion of the development of the software, it has to be tested before going to the deployment phase so in this phase the software goes through the automated test process to get feedback on business risks associated with a software release candidate as rapidly as possible.
The most used tools for automated testing are Selenium, TestNG, JUnit, etc. These tools allow QAs to check multiple codebases thoroughly in parallel to make sure that there are not any flaws within the functionality.
3) Continuous Integration

In this phase of software development, if the developer commits changes in source code, every commit is built and allows early detection of problems if any because it goes through various tests like unit tests, integration/system tests.
The most widely used tool for this phase is Jenkins. Jenkins fetches the updated code whenever the is a change in a git repository, it prepares a build of the code in the form of a jar for execution. This build is then forwarded to the test phase or deployment/production phase.
4) Continuous Deployment
After the integration phase, the code is deployed to the production servers. Here containerization tools are used for producing consistency across development, test, staging, and production environment, they also help in scaling up and down servers swiftly. The commonly used tool for containerization is docker.
5) Continuous Monitoring
In this phase, you continuously monitor the performance of the software deployed. Here the important information of the software is recorded, and this information is used to resolve any issue/problems that occurred, and it is resolved.
The tools used for monitoring are Splunk, ELK Stack, Nagios, NewRelic, and Sensu. This tool monitors the performance of the software and servers, also checks the health of the system closely.
Check Out: Azure Data Factory Interview Questions and Answers.
What Is Data Engineering?
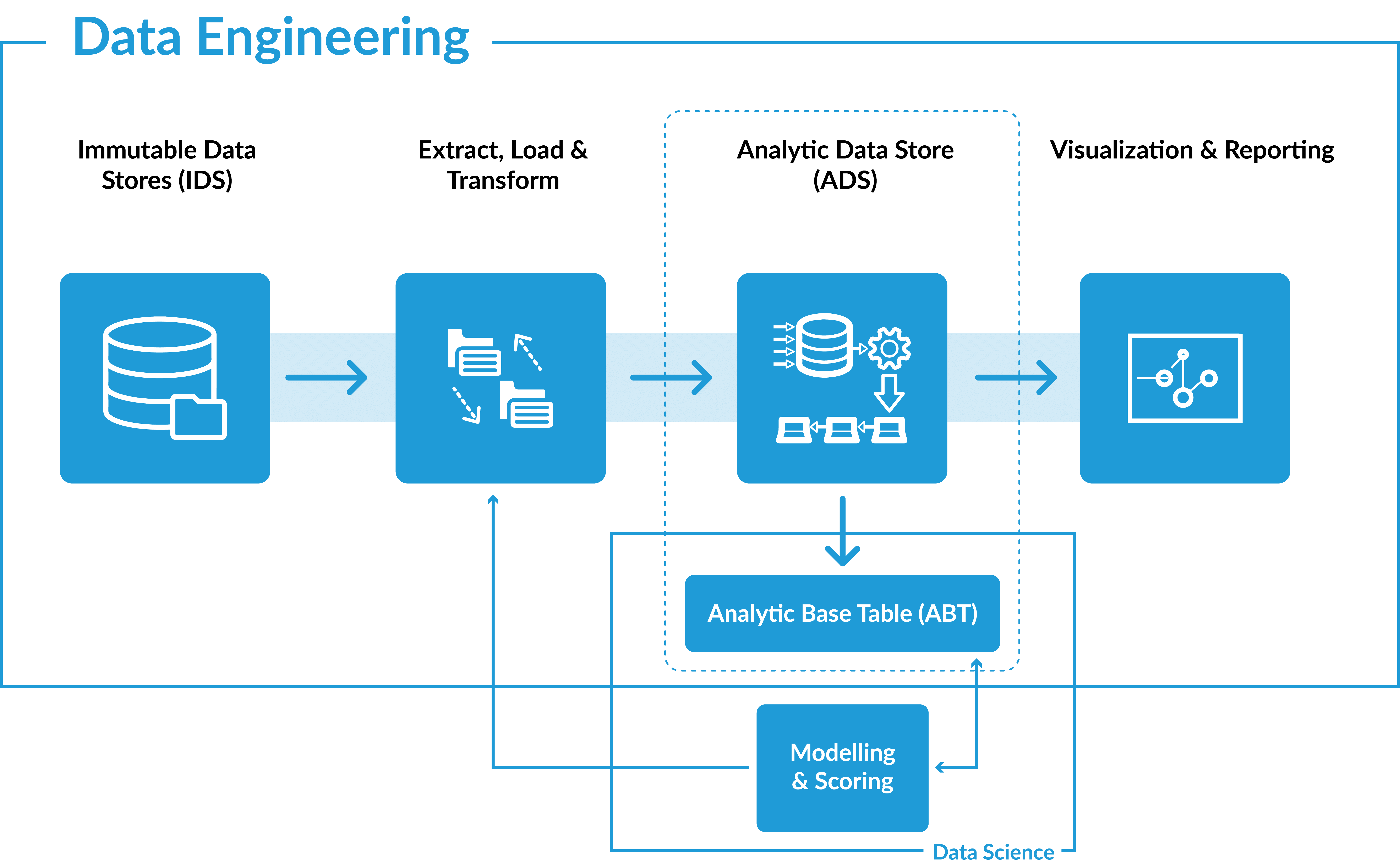 Data engineering is a set of practices performed by data engineers to transform (ETL) the raw data available into useful data for data analysts and data scientists for taking better decisions for any organization.
Data engineering is a set of practices performed by data engineers to transform (ETL) the raw data available into useful data for data analysts and data scientists for taking better decisions for any organization.
What Is DataOps?
DataOps is a process of automating the data-driven cycle used by analytics data teams by creating an automated pipeline. It improves the quality and reduces the cycle time of data analytics.
Difference between DevOps vs DataOps
The difference Between DataOps and DevOps is: |
||
|---|---|---|
| DevOps | DataOps | |
| The delivery value of DevOps is software engineering. | The delivery value of DataOps is data engineering, analytics, business intelligence, data science. | |
| The quality assurance of DevOps is code reviews, continuous testing, monitoring. | The quality assurance of DataOps is data governance, process control. |
Why DataOps For Data-Engineering?
DataOps helps the data engineers by enabling end-end orchestration of pipeline, (spark, SQL, hive) code and organizational data environments. It makes collaboration within the teams to involve and solve customer needs. DataOps helps data engineers to collaborate with data stakeholders and helping them to achieve scalability, reliability, agility.
How DataOps Is Used In Azure?
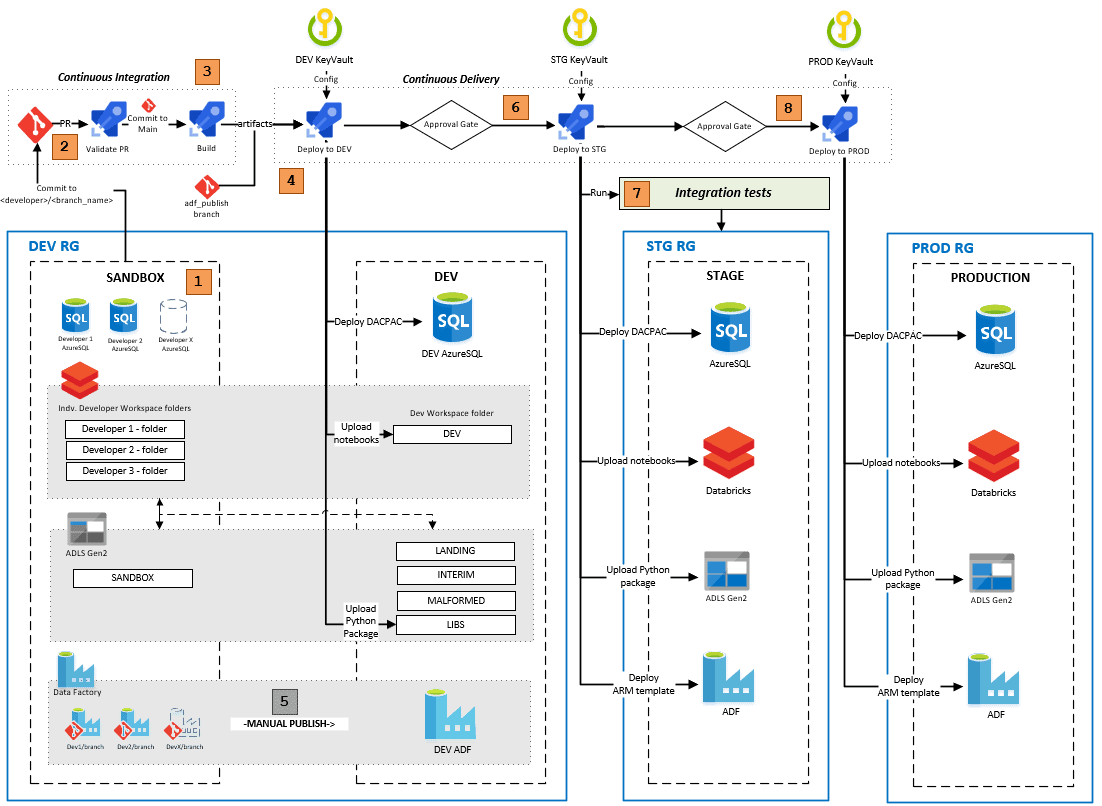 Services used here are:
Services used here are:
- Azure Data Factory
- Azure Databricks
- Azure Data Lake Gen2
- Azure Synapse Analytics (formerly SQLDW)
- Azure DevOps
- Application Insights
- PowerBI
Key Learnings:
1) Use of data tiers in datalake
Generally, you want to divide your data lake into three major areas which contain your bronze, silver, and gold datasets.
- Bronze tier: It is where the raw data is kept in a data lake without any data transformation applied
- Silver-tier: In the silver tier, the data is cleansed, and semi-processed. These conform to a pre-defined schema and might have data augmentation required. The data is normally used by data-scientist who don’t require fully cleaned data.
- Gold tier: These are fully cleaned data used by business users. These are structured in fact and dimension tables.
2) Validate data early in the pipeline
- Data validation is done between the bronze and silver datasets. You may assure that all subsequent datasets conform to a certain schema by validating early in your process. This also can potentially prevent data pipeline failures in cases of unexpected changes to the input data.
- Data that doesn’t pass through this validation is stored as a malformed record for diagnostic purposes.
3) Make your data pipelines replayable and idempotent
- Silver and Gold datasets can get corrupted due to several reasons such as unintended bugs, unexpected input data changes, and more. By making data pipelines replayable and idempotent, you can recover from this state through the deployment of code fixes and replaying the data pipelines.
4) Ensure data transformation code is testable
- Abstracting away data transformation code from data access code is key to ensuring unit tests can be written against data transformation logic. Moving transformation code from notebooks to packages is an example of this.
5) Have a CI/CD pipeline
- This includes all the artifacts needed to build a data pipeline from scratch in source control. This includes infrastructure as code artifacts, database objects (schema definitions, functions, stored procedures, etc.), reference/application data, data pipeline definitions, and data validation and transformation logic.
- There should also be a safe, repeatable process to move changes through dev, test, and finally production.
6) Secure and centralized configuration
- Maintain a central, secure location for sensitive configurations such as database connection strings that can be accessed by the appropriate services within the specific environment. This can be done by azure key vault.
7) Monitor infrastructure, pipelines, and data
- A proper monitoring solution should be in place to ensure failures are identified, diagnosed, and addressed on time.
What Are The Benefits Of DataOps?
The benefits of DataOps are listed below:
- Reduces the complexity of data analytics end-end orchestration and operations.
- It improves the data quality.
- It reduces the data life cycle of data cleaning, processing, and loading.
- It optimizes the data collaboration within the DevOps team.
- It will go through production-like tests and patterns which enhances testing.
- Can solve the problems faster than the traditional method.
- It ensures the protection of customer data and hence no risks.
Conclusion
In short, we have to say that DataOps is not just DevOps for development. It is a set of practices and methods that can add value to the data you collect, encourage collaboration, coordinate processes from an on-premises deployment to the cloud, ensure controlled and secure results, and ensure data security. Allows monitoring of each process and quality checks at different stages to ensure the reliability of data. Reduce delay and time. Optimize the loading and cleaning process and reduce the indirect life cycle, make work easier and faster, and evolve with the latest trends, etc.
Related/References
- DP 203 Exam | Microsoft Certified: Azure Data Engineer Associate
- [DOFD] DevOps Foundation Certification Exam: Everything You Need To Know
- CI/CD Pipeline | Continuous Integration | Continuous Deployment
- What Is DevOps?
- [Self-Study Guide] Exam DP-203: Data Engineering on Microsoft Azure
Next Task For You
In our Azure Data Engineer training program, we will cover 28 Hands-On Labs. If you want to begin your journey towards becoming a Microsoft Certified: Azure Data Engineer Associate by checking out our FREE CLASS.

![Microsoft Agentic AI Business Solutions Architect [AB-100] | K21 Academy](https://test.k21academy.com/wp-content/uploads/2025/11/Microsoft-Agentic-AI-Business-Solutions-Architect-AB-100-Exam-Overview1.png)



