


![]()
Azure Data Factory gives a variety of instruments that empowers you to change and purify information to your business necessities. Numerous normal change errands can be performed code-free, utilizing the Mapping Data Flow task.
This blog post will go through some quick tips including Q/A and related blog posts on the topics that we covered in the Azure Data Engineer Day 6 Live Session which will help you gain a better understanding and make it easier for you to
The previous week, In Day 5 session we got an overview of concepts of Ingest and load data into the data warehouse where we have covered topics like Workload Management, PolyBase & Copy Activity in Azure Data Factory.
In this week, Day 6 Live Session of the Training Program, we covered the concepts of Module 6: Transform data with Azure Data Factory or Azure Synapse Pipelines where we have covered topics like Azure Data Factory or Azure Synapse Pipelines.
We also covered hands-on, Transform Data with Azure Data Factory or Azure Synapse Pipelines, Code-Free Transformation At Scale With Azure Synapse Pipelines out of our 27 extensive labs.
So, here are some FAQs asked during the Day 6 Live session from Module 6 Of DP203.
>Transform data with Azure Data Factory or Azure Synapse Pipelines
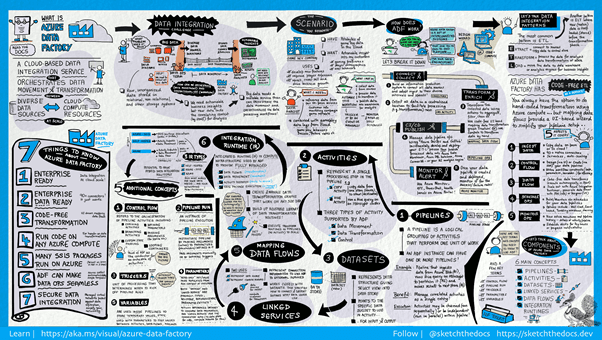
In this module, we have examined Azure Data Factory and the core components that enable you to create large-scale data ingestion solutions in the cloud.
The components of Azure Data Factory:
1. Linked services
2. Datasets
3. Activity
4. Pipeline
5. Triggers
6. Pipeline runs
7. Parameters
8. Control flow
9. Integration Runtime
 Source: Microsoft
Source: Microsoft
Check Out: Azure Data Factory Interview Questions and Answers.
Lab: Code-Free Transformation at Scale with Azure Synapse Pipelines
You’ll create the required objects; namely SQL tables, that will be used to store the data that is ingested by the mapping data flow. Then you will define the required linked services to connect to the data sources to consume the data, followed by pointing to the datasets within the linked services. Note that you will be dealing with poorly formatted data while creating these datasets, and how to handle it in a linked service.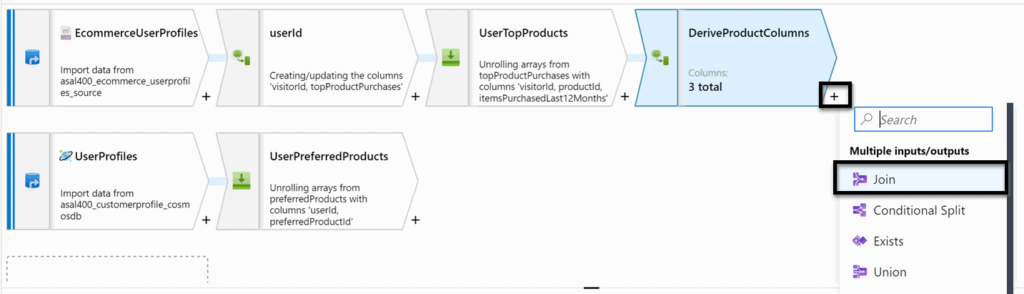 Q3. What’s the Difference between Hadoop and a Data Lake?
Q3. What’s the Difference between Hadoop and a Data Lake?
Ans: Hadoop is a technology that can be used to build data lakes. A data lake is an architecture, while Hadoop is a component of that architecture. In other words, Hadoop is the platform for data lakes. So, the relationship is complementary, not competitive.
Q4. I deleted my old VM. Does that mean, I must do Lab 0 again and then Lab 04?
Ans. No, you can start with lab 04 but you must use the same resource. So, you have to create a new VM, and other resources need not be recreated.
Q5. What does publish do?
Ans. It contains the code, specifically, the JSON code related to all the ADF pipelines and their components that are published to the Data Factory service.
Q6. How do we share reports/charts with the business team in a real environment?
Ans. After configuring a dashboard, you can publish it and share it with other users in your organization. You can allow others to view your dashboard by using Azure role-based access control (Azure RBAC)
Q7. How is it taking the unique product IDs? Multiple rows may have one product purchased multiple times.
Ans. In this case, one product ID is occurring only once but we may have to list unique products in the scenario where one product is purchased multiple times.
Q8. Can we relate the HASH key with the Partition Key of Cosmos DB?
Ans. Azure Cosmos DB uses hash-based partitioning to spread logical partitions across physical partitions. Azure Cosmos DB hashes the partition key value of an item. The hashed result determines the physical partition.
Q9. How about a non-clustered index?
Ans. A non-clustered index doesn’t sort the physical data inside the table. In fact, a non-clustered index is stored in one place and table data is stored in another place.
Q10. Pipelines are optimal choices for automation?
Ans. Pipelines automatically build and test code projects to make them available to others. It works with just about any language or project type. For pipelines, deployment is the action of running the tasks for one stage, which can include running automated tests, deploying build artifacts, and any other actions are specified for that stage.
Q11. COPY INTO can be used in synapse SQL script?
Ans. COPY Into can be used in synapse SQL script as it loads data from staged files to an existing table, a new method of loading data from storage directly into a target object with lesser permissions required and no additional objects or credentials to be created to load the data.
Q12. What strategy would be adopted when there is a need for the frequent queries of the latest data but not like IoT? The frequency could be 15 minutes.
Ans: You can have a scheduled ADF or azure synapse pipeline with activities that will run after every 15 mins. Depending upon your scenario you can either load the data onto datalake / other sink or maybe just do a quick look upon that data.
Feedback Received…
Here is some positive feedback from our trainees who attended the session.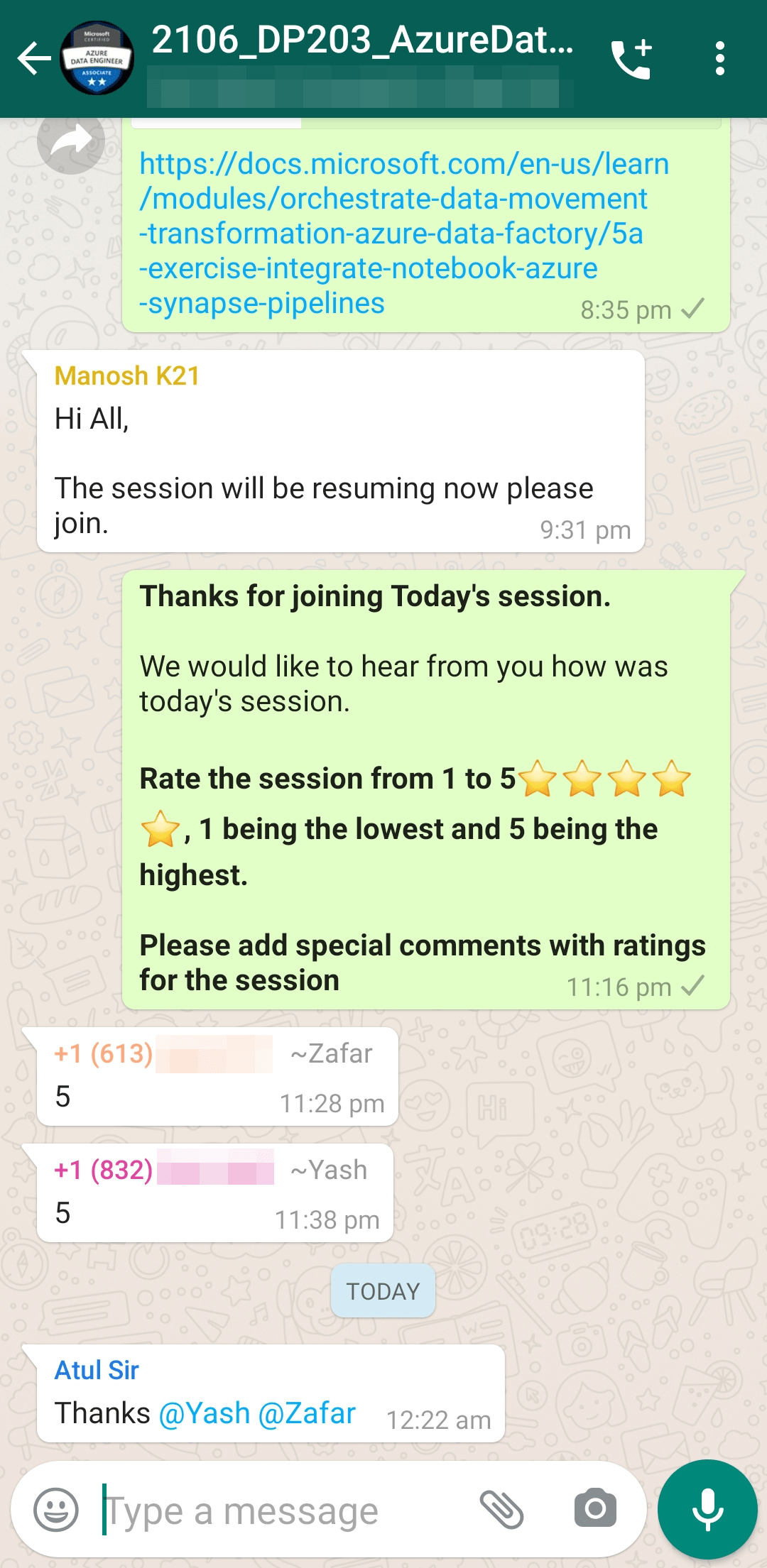
Quiz Time (Sample Exam Questions)!
With our Azure Data Engineer Training Program, we cover 500+ sample exam questions to help you prepare for the [DP-203] Certification.
Check out one of the questions and see if you can crack this…
Ques: Your team has created a new Azure Data Factory environment. You have to analyze the pipeline executions. Trends need to be identified in execution duration over the past 30 days. You need to create a solution that would ensure that data can be queried from Azure Log Analytics.
Which of the following would you choose as the Log type when setting up the diagnostic setting for Azure Data Factory?
A. ActivityRuns
B. AllMetrics
C. PipelineRuns
D. TriggerRuns
Comment with your answer & we will tell you if you are correct or not!
References
- Microsoft Certified Azure Data Engineer Associate | DP 203 | Step By Step Activity Guides (Hands-On Labs)
- Azure Data Lake For Beginners: All you Need To Know
- Azure Databricks For Beginners
- Azure Data Factory For Beginners
- Azure Synapse Analytics (Azure SQL Data Warehouse)
- Azure Data Engineer [DP-203] Q/A | Day 1 Live Session Review
- Azure Data Engineer [DP-203] Q/A | Day 2 Live Session Review
- Azure Data Engineer [DP-203] Q/A | Day 3 Live Session Review
- Azure Data Engineer [DP-203] Q/A | Day 4 Live Session Review
- Azure Data Engineer [DP-203] Q/A | Day 5 Live Session Review
Next Task For You
In our Azure Data Engineer training program, we will cover 28 Hands-On Labs. If you want to begin your journey towards becoming a Microsoft Certified: Azure Data Engineer Associate by checking out our FREE CLASS.

![Microsoft Agentic AI Business Solutions Architect [AB-100] | K21 Academy](https://test.k21academy.com/wp-content/uploads/2025/11/Microsoft-Agentic-AI-Business-Solutions-Architect-AB-100-Exam-Overview1.png)


