




![]()
In this blog, we are going to discuss the main Machine Learning Algorithms and their uses.
Machine learning may be a methodology of data analysis that automates analytical model building. It’s a branch of Artificial Intelligence that supports the concept that systems will learn from data, determine patterns, and create selections with the lowest human intervention.
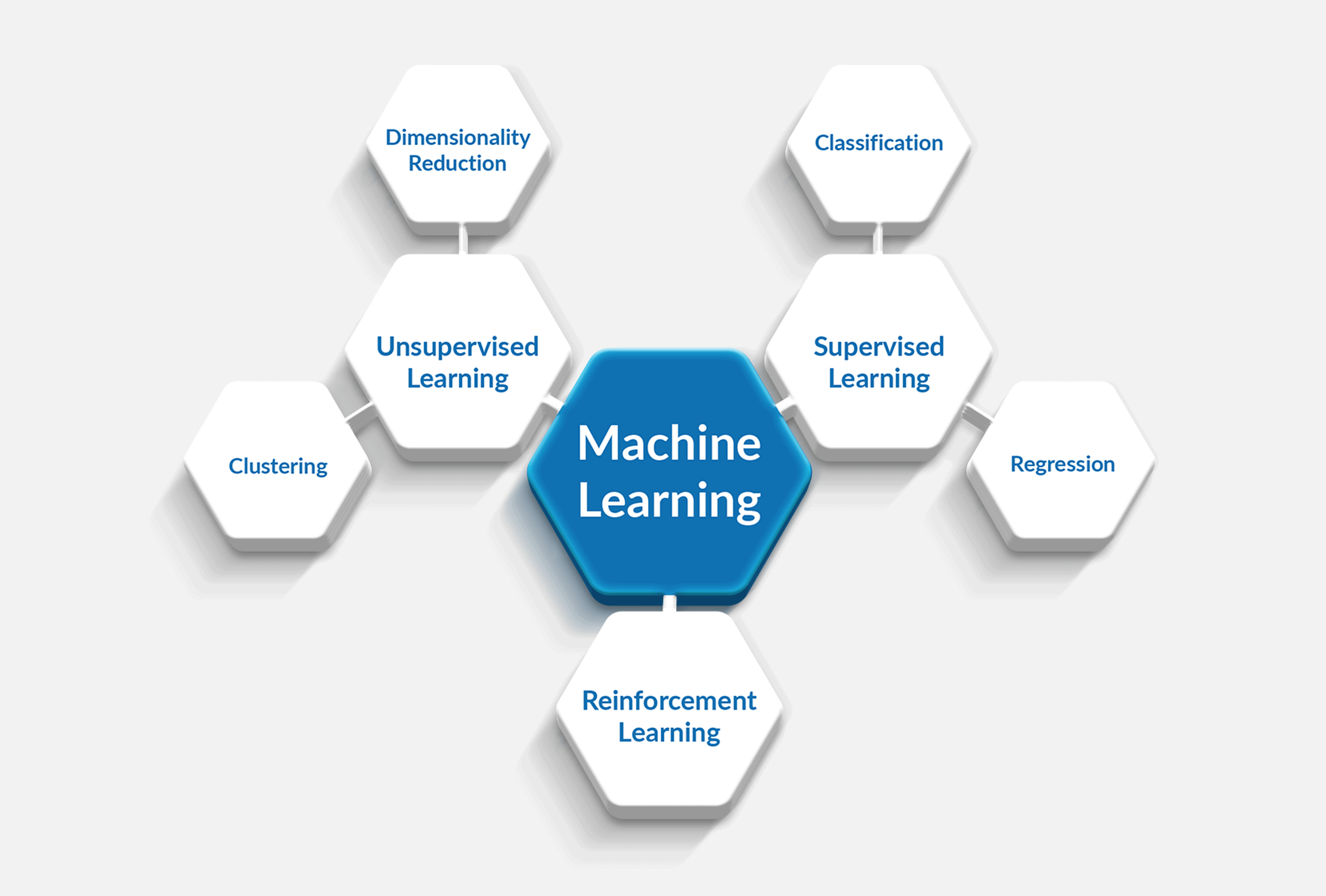
Types of Machine Learning
There are three main categories of machine learning:
- Supervised learning
- Unsupervised learning
- Reinforcement learning
Supervised Learning
Supervised learning is similar to a child learning under the guidance of a supervisor or a teacher.
Here are some of the most important supervised learning algorithms and their uses:
Text Analytics
Text Analytics is the process of drawing meaning out of written communication.
Derives high-quality information from the text – Answers questions like, What info is in this text?
Text Analytics |
|
|---|---|
| Algorithms | Why should we use |
| Extract N-Gram Features from Text | Creates a dictionary of n-grams from a column of free text. |
| Feature Hashing. | Converts text data to integer encoded features using the Vowpal Wabbit library. |
| Preprocess Text | Performs cleaning operations on text, like removal of stop-words, and case normalization. |
| Word2Vector | Converts words to values for use in NLP tasks, like recommender, named entity recognition, and machine translation. |
Image Classification
Image classification refers to the task of extracting data categories from a multiband formation image.
Classifies pictures with well-liked networks – Answers queries like: What will this image represent?
Image Classification |
|
|---|---|
| Algorithms | Why should we use |
| DenseNet | Because it has High accuracy and better efficiency. |
Regression
Regression may be a method utilized in finance, investing, and different disciplines that attempt to verify the strength and character of the link between one dependent variable (usually denoted by Y) and a series of other variables (known as independent variables).
Makes forecasts by estimating the relationship between values – Answers queries like, what quantity or however many?
Regression |
|
|---|---|
| Algorithms | Why should we use |
| Fast Forest Quantile Regression. | Predicts a distribution. |
| Poisson Regression. | Predicts event counts. |
| Linear Regression. | Fast training, linear model. |
| Bayesian Linear Regression | Linear model, small data sets. |
| Decision Forest Regression | Accurate, fast training times. |
| Neural Network Regression | Accurate, long training times. |
| Boosted Decision Tree Regression | Accurate, fast training times, large memory footprint. |
Two-Class Classification
It is a classification of two groups, i.e. classifies objects in at most two classes.
Answers simple two-choice questions, like yes or no, true or false – Answers questions like Is this A or B?
Two-Class Classification |
|
|---|---|
| Algorithms | Why should we use |
| Two-Class Support Vector Machine | Under 100 features, linear model. |
| Two-Class Averaged Perceptron | Fast training, linear model. |
| Two-Class Decision Forest | Accurate, fast training. |
| Two-Class Logistic Regression | Fast training, linear model. |
| Two-Class Boosted Decision Tree | Accurate, fast training, large memory footprint. |
| Two-Class Neural Network | Accurate, long training times. |
Multiclass Classification
There will be any range of categories in it, i.e., classify the item into quite 2 categories.
Answers complicated queries with multiple attainable answers – Answers queries like: Is that this A or B or C or D?
Multiclass Classification |
|
|---|---|
| Algorithms | Why should we use |
| Multiclass Logistic Regression | Fast training times, linear model. |
| Multiclass Neural Network | Accuracy, long training times. |
| Multiclass Decision Forest | Accuracy, fast training times. |
| One-vs-All Multiclass | Depends on the two-class classifier. |
| Multiclass Boosted Decision Tree | Non-parametric, fast training times, and scalable. |
Anomaly Detection
Anomaly detection is named the identification of things or events that don’t adjust to an expected pattern or different items gift in an exceeding dataset.
Identifies and predicts rare or uncommon information points – Answers the question: is that this weird?
Anomaly Detection |
|
|---|---|
| Algorithms | Why should we use |
| One Class SVM | Under 100 features, aggressive boundary. |
| PCA-Based Anomaly Detection | Fast training times. |
Check Out: Best Data Science Interview Questions.
Unsupervised Learning
Unsupervised learning is similar to a child trying to figure out things all by himself, without any guidance or supervision.
It uses unlabeled data and tries to predict unknown patterns in the data.
Types and uses of unsupervised learning are:
Clustering
Clustering is the task of dividing the population or data points into a spread of groups such data points among identical groups are like completely different data points among identical clusters than those in numerous groups. In simple words, the aim is to segregate groups with similar traits and assign them into clusters.
Separates similar data points into intuitive teams – Answers queries like: however, is that this organized?
Clustering |
|
|---|---|
| Algorithms | Why should we use |
| K-Means | Unsupervised learning. |
Recommenders
Recommender systems are systems that are designed to suggest things to the user supported by many alternative factors. These systems predict the foremost doubtless product that the users are presumably to buy and are of interest to.
Predicts what somebody will be curious about – Answers the question: what’s going to they have an interest in?
Recommenders |
|
|---|---|
| Algorithms | Why should we use |
| SVD Recommender | Collaborative filtering, better performance with lower cost by reducing the dimensionality. |
Check Out: Our blog post on DevOps for Data Science.
Real-world machine learning use cases:
Here are just a few examples of machine learning you might encounter every day :
Use Cases |
|
|---|---|
| Speech Recognition | It is also known as automatic speech recognition (ASR), computer speech recognition, or speech-to-text, and it is a capability that uses natural language processing (NLP) to process human speech into a written format. Many mobile devices incorporate speech recognition into their systems to conduct voice searches—e.g. Siri—or provide more accessibility around texting. |
| Automated stock trading | Designed to optimize stock portfolios, AI-driven high-frequency trading platforms make thousands or even millions of trades per day without human intervention. |
| Computer Vision | This AI technology allows computers and systems to derive purposeful data from digital pictures, videos, and different visual inputs, and by supporting those inputs, it will take action. This ability to supply recommendations distinguishes it from image recognition tasks. steam-powered by convolutional neural networks, laptop vision has applications among ikon tagging in social media, radiology imaging, and self-driving cars in the automotive trade. |
| Transportation | Analyzing information to spot patterns and trends is vital to the transportation trade, which depends on creating routes additional economical and predicting potential issues to extend profit. the information analysis and modeling aspects of the machine learning area unit are vital tools for delivery firms, public transportation, and different transportation organizations. |
| Customer Service | Online chatbots are commutation human agents on the client journey. They answer frequently asked queries (FAQs) around topics, like shipping, or offer customized recommendations, cross-selling merchandise, or suggesting sizes for users, ever-changing the manner we expect regarding client engagement across websites and social media platforms. Examples include electronic messaging bots on e-commerce sites with virtual agents, electronic messaging apps, like Slack and Facebook Messenger, and tasks typically done by virtual assistants and voice assistants. |
| Recommendation Engines | Using past consumption behavior data, AI algorithms will facilitate data trends that may be wont to develop simpler cross-selling ways. this is used to create relevant add-on recommendations to customers throughout the checkout method for online retailers. |
| Financial services | Banks and different businesses within the monetary business use machine learning technology for 2 key purposes: to spot vital insights into knowledge, and to forestall fraud. The insights will determine investment opportunities or facilitate investors’ grasp once to trade. data processing may determine shoppers with bad profiles or use cyber police work to pinpoint warning signs of fraud. |
| Health care | Machine learning may be a fast-growing trend within the healthcare business, due to the appearance of wearable devices and sensors that may use knowledge to assess a patient’s health in a period. The technology may facilitate physicians to analyze knowledge to spot trends or red flags that will result in improved diagnoses and treatment. |
Machine Learning Algorithms List
In machine learning, various algorithms are used to handle diverse data and solve different problems. Some popular algorithms include Linear Regression, which models relationships between variables; Logistic Regression for binary classification tasks; and Decision Trees, which create branches for each decision path. Random Forests, a collection of decision trees, improve accuracy by reducing overfitting. Support Vector Machines (SVM) are effective for classification by finding the best boundary between data points. K-Nearest Neighbors (KNN) relies on data proximity for predictions, while K-Means Clustering groups data into clusters. Finally, Neural Networks mimic human brain functions, excelling in tasks like image and speech recognition.
Machine Learning Algorithms For Prediction
Machine learning algorithms for prediction empower data-driven insights by identifying patterns within large datasets. Common predictive algorithms include linear regression, which models relationships between variables for straightforward predictions, and decision trees, which split data into branches to make decisions based on specific criteria. Random forests combine multiple decision trees to improve accuracy, while support vector machines (SVMs) classify data by finding optimal boundaries between classes. Neural networks, especially deep learning models, excel at complex pattern recognition in unstructured data like images or text. By selecting the right algorithm, businesses can predict trends, customer behaviors, and potential outcomes, enhancing decision-making processes.
FAQs
How do you choose the right machine learning algorithm for a problem?
Choosing the right machine learning algorithm depends on the data, the problem type, and performance goals. Consider the data size, complexity, interpretability, and computation resources for optimal results.
How does linear regression work?
Linear regression models the relationship between two variables by fitting a line through data points. It predicts an output by calculating a best-fit line, minimizing prediction errors.
What is a random forest?
A random forest is an ensemble machine learning method that builds multiple decision trees and combines their outputs for improved accuracy and robustness, making it effective for classification and regression tasks.
How does a decision tree work?
A decision tree works by splitting data into branches based on features, creating if-then conditions. Each split aims to improve prediction accuracy, leading to final leaf nodes with outcomes.
What are support vector machines (SVM), and how do they work?
Support Vector Machines (SVM) are supervised machine learning models used for classification and regression. They work by finding a hyperplane that best separates data points from different classes, maximizing the margin between them for improved accuracy and robustness.
How do decision trees work in machine learning?
Decision trees in machine learning split data into branches based on feature values, creating a structure that resembles a tree. Each branch decision narrows down possibilities, improving predictive accuracy.
How does hierarchical clustering differ from K-means clustering?
Hierarchical clustering builds a hierarchy of clusters by successively merging or splitting them, whereas K-means assigns data into a set number of clusters based on centroids, requiring predefined clusters.
Conclusion
By now, you would have had a thorough understanding of what Machine Learning is and how this concept has evolved over some time. Artificial Intelligence will be the driving force for innovations in the upcoming time and have the potential to solve the world’s striking problems from various domains.
Related/References
- Join Our Generative AI Whatsapp Community
- Azure AI/ML Certifications: Everything You Need to Know
- Azure GenAI/ML : Step-by-Step Activity Guide (Hands-on Lab) & Project Work
- DP 100 Exam | Microsoft Certified Azure Data Scientist Associate
- Step By Step Activity Guides (Hands-On Labs) for DP-100 certification
- Microsoft Azure AI Fundamentals – AI-900 Exam Detailed Overview
- Microsoft Azure Data Scientist DP-100 FAQ
- [DP-100] Design & Implement a Data Science Solution on Azure Question & Answers/Day 1 Live Session Review
- Introduction To Data Science and Machine Learning
Next Task: Enhance Your Azure AI/ML Skills

![Microsoft Agentic AI Business Solutions Architect [AB-100] | K21 Academy](https://test.k21academy.com/wp-content/uploads/2025/11/Microsoft-Agentic-AI-Business-Solutions-Architect-AB-100-Exam-Overview1.png)



