


![]()
In this blog, I will cover the Q&As of Python for Data Science (AI/ML) and Data Engineer Training covering Introduction to Apache Spark in Python.
This blog will help to clear your concepts in Python.
The previous week, In Day 7 Live Session, we have covered the basic concepts of Matplotlib and Plotly in Python.
So, here are some of the Q & As asked during the Live session from Module 10: Introduction to Apache Spark.
Apache Spark
Apache Spark is a lightning-fast cluster computing technology, designed for fast computation. It is based on Hadoop MapReduce and it extends the MapReduce model to efficiently use it for more types of computations, which includes interactive queries and stream processing. The main feature of Spark is its in-memory cluster computing that increases the processing speed of an application.
![]()
Q1: How does Spark rise?
Ans: Storing data electronically in RAM rather than storing it magnetically on disks makes it more volatile and this is where the spark comes to play.
Q2: What is RDD (Resilient Distributed Datasets)
Ans: Resilient Distributed Datasets (RDD) is a fundamental data structure of Spark. It is an immutable distributed collection of objects. It supports in-memory computation.
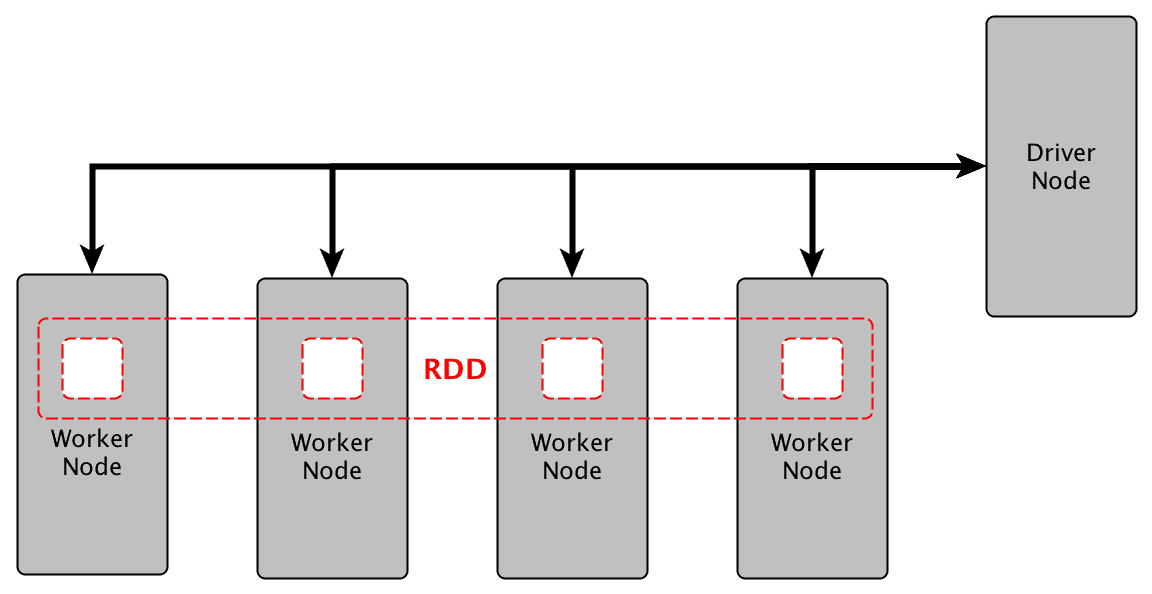
- RDD is a fundamental data structure of Spark.
- Each dataset in RDD is divided into logical partitions, which may be computed on different nodes of the cluster.
- Formally an RDD is a read-only partitioned collection of objects.
- RDD is a fault-tolerant collection of elements that can be operated on in parallel.
- There are two ways to create RDDs-parallelizing an existing collection in our driver/referencing a dataset in external storage.
- In Hadoop, we store the data as blocks and store them in different data nodes. In Spark instead of following the above approach we make partitions of the RDDs and store them in worker nodes which are computed in parallel across all the nodes.
- RDDs perform two types of operations: transformations which creates a new dataset from the previous RDD and actions which return a value to the driver program after performing the computation on the dataset.
- RDDs keep a track of transformations and checks them periodically. If a node fails it can rebuild the lost RDD partition on the other nodes in parallel.
Q3: What are the components of Apache Spark?
Ans: Apache Spark consists of Spark Core Engine, Spark SQL, Spark Streaming, MLlib and GraphX. You can use Spark Core Engine along with any of the other five components mentioned above. It is not necessary to use all the Spark components together. Depending on the use case and application, any one or more of these can be used along with Spark Core.
Let us look at each of these components in detail.
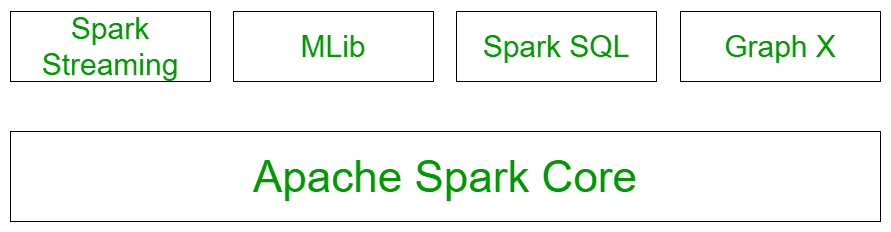
- Apache-spark core: Spark Core is the underlying general execution engine for the Spark platform that all other functionality is built upon. It provides in-memory computing and referencing datasets.
- Spark Streaming: Spark Streaming leverages Spark’s core fast scheduling capability to perform streaming analytics. It ingests data in mini-batches and performs RDD transformations on those mini-batches of data. RDD has distributed a collection of objects.
- MLlib(machine learning library): MLLib is a distributed ML framework above spark because of the distributed processing power of spark.
- Spark SQL: This is a component on top of spark core that introduces a new data abstraction called SCHEMARDD, which provides support for structured and semi-structured data.
- GraphX: GraphX is a distributed graph-processing framework on top of Spark. It provides an API for expressing graph computation that can model the user-defined graphs by using Prgel abstraction API.
Q4: What is a Spark context?
Ans: A SparkContext represents the connection to a Spark cluster, and can be used to create RDDs, accumulators and broadcast variables on that cluster. Only one SparkContext should be active per JVM. The main functions are :
- main entry point for spark functionality.
- created for you in spark shells as variable spark content
- in standalone programs, we can make our own.
Also Read: Our blog post on Python Pandas.
Q5: What is Spark Transformation?
Ans: Any function that returns an RDD is a transformation, further we can say that Transformations are functions that create a new dataset from an existing one bypassing each dataset element through a function. RDD transformations return a pointer to the new RDD and allow you to create dependencies between RDDs.
All transformations in Spark are lazy. they do not compute their result right away. The transformations are only computed when an action requires a result that needs to be returned to the driver program. Therefore, RDD transformation is not a set of data but is a step of a program that just tells Spark how to get data and what to do with it. -eg: map, filter map.
| Types of Transformation operations | |
|---|---|
| flatmap | flat map will take iterable data as input and returns the RDD as the contents of the iterator. |
| filter | filter returns an RDD which meets the filter condition. |
| Reducebykey | reducebykey takes a pair of key and value pairs and combines all the values for each unique key. |
| foreach | the foreach operation is used to iterate every element in the RDD. |
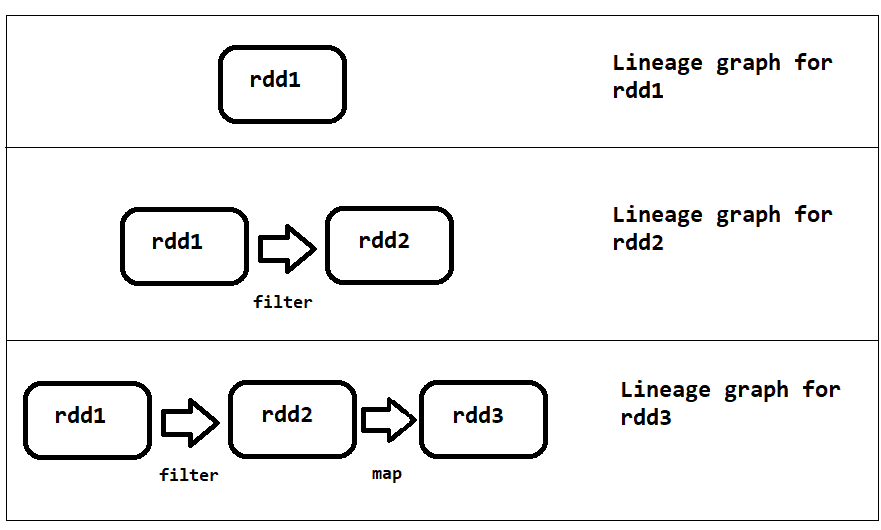
Q6: What is the lineage graph in spark ?
Ans: When a new RDD has been created from an existing RDD, that new RDD contains a pointer to the parent RDD all the dependencies between the RDDs will be logged in the graph.This graph is called the Lineage Graph.
Q7: What is DAG in Spark?
Ans: DAG stands for Directed Acyclic Graph. DAG in Apache Spark is a combination of vertices as well as Edges. In Dag, vertices represent the RDDs and the edges represent the operation to be applied on RDD. Every edge in DAG is directed from earlier to later in the sequence. When we call an action the created DAG is submitted to DAG Scheduler which further splits the graph into stages of task.
PySpark
PySpark is a Python API to support Python with Apache Spark. PySpark provides the Py4j library, with the help of this library, Python can be easily integrated with Apache Spark. PySpark plays an essential role when it needs to work with a vast dataset or analyze them.

Q8: What are the main characteristics of (Py)Spark?
Ans: Some of the main characteristics of (Py)Spark are:
- Here Nodes are abstracted that says not possible to address an individual node.
- Also, the Network is abstracted, which means there is only implicit communication possible.
- Moreover, it is based on Map-Reduce, which means the programmer provides a map and a reduce function here.
- And, PySpark is one of the API for Spark.
Q9: What are the Prerequisites to learn PySpark?
Ans: It is being assumed that the readers are already aware of what a programming language and a framework are, before proceeding with the various concepts given in this tutorial. Also, if the readers have some knowledge of Spark and Python in advance, it will be very helpful.
Q10: What are the Pros and Cons of Pyspark?
Ans: Some of the benefits of using PySpark are:
- For simple problems, it is very simple to write parallelized code.
- Also, it handles Synchronization points as well as errors.
- Moreover, in Spark, many useful algorithms are already implemented.
Some of the limitations on using PySpark are:
- It is difficult to express a problem in MapReduce fashion sometimes.
- Also, Sometimes, it is not as efficient as other programming models.
Q11: Name algorithms supported in PySpark?
Ans: There are several algorithms in PySpark:
- mllib.classification
- mllib.clustering
- mllib.fpm
- mllib.linalg
- mllib.recommendation
- spark.mllib
- Mllib.regression
Related References
- Python Methods and Functions Q & A: Day 3 Live Session Review
- Python OOPs Concepts, Error And Exception Handling Q & A: Day 4 Live Session Review
- Python Decorators and Generators Q & A: Day 5 Live Session Review
- NumPy and Pandas Q & A: Day 6 Live Session Review
- Python For Beginners: Overview, Features & Career Opportunities
Next Task For You…
Python’s growth is very promising in the near future. Gaining the right skills through the right platform will get you to the perfect job.
We are launching our course Python For Data Science (AI/ML) & Data Engineers (Python For Beginners) which will you help and guide you towards your first steps to Python. Join our FREE CLASS to know more about it.

![Microsoft Agentic AI Business Solutions Architect [AB-100] | K21 Academy](https://test.k21academy.com/wp-content/uploads/2025/11/Microsoft-Agentic-AI-Business-Solutions-Architect-AB-100-Exam-Overview1.png)


