This blog post will cover some quick tips including FAQs on the topics that we covered in the Day 5 live session which will help to clear Certification [DP-100] & get a better-paid job.
In the previous week’s sessions, in Day 4 session we got an overview of Orchestrating Operations with Pipelines. And in this week’s Day 5 Live Session of the AI/ML & Azure Data Scientist Certification [DP-100] training program, we covered the concepts of Deploy and Consuming Modelsand Training Optimal Models. We also covered hands-onLab 13, Lab 14, Lab 15 and Lab 16 out of our 15+ extensive labs.
So, here are some of the Q & As asked during the Live session fromModule 7: Deploy and Consuming Models and Module 8: Training Optimal Models & Hands-on Lab on Inferencing Services and Hyperparameters of Microsoft Azure Data Scientist [DP-100].
Deploy and Consuming Models
In Previous Modules, you have created the Pipelines and Here you trained your model. Now, it’s time to generate predictions based on user input. In this module, you will:
Create a real-time inference pipeline.
Create an inferencing cluster.
Deploy the real-time endpoint.
Test the real-time endpoint.
Q1: What do you mean by Real-time inferencing in Azure Machine Learning? A: In machine learning, inferencing refers to the use of a trained model to predict labels for new data on which the model has not been trained. Often, the model is deployed as part of a service that enables applications to request immediate, or real-time, predictions for individual, or small numbers of data observations.
In Azure Machine Learning, you’ll be able to produce real-time inferencing solutions by deploying a model as a service, hosted during a containerized platform, like Azure Kubernetes Services (AKS).
Q2: What do you understand by Batch inferencing?
A: In several production eventualities, long-running tasks that care for massive volumes of data are performed as batch operations. In machine learning, batch inferencing is employed to use a predictive model to multiple cases asynchronously – typically writing the results to a file or info.
In Azure Machine Learning, you’ll be able to implement batch inferencing solutions by making a pipeline that features a step to scan the input data, load a registered model, predict labels, and write the results as its output.
Q3: What are the practical applications of batch processing?
A: Practical applications of batch processing are: Transactions, Reporting, Research, process financial data in batches.
Q4: What are the different compute Targets?
A: There are 3 main compute targets :
Compute clusters are different from compute instances with their ability to have one or more compute nodes. These compute nodes can be created with our desired hardware configurations.
Compute instance can be defined as a virtual machine fully loaded with data science and machine learning essentials that you can use right out of the box.
The Azure Kubernetes Service (AKS) cluster provides a GPU resource that’s employed by the model for inference. Inference, or model rating, is that the part wherever the deployed model is employed to create predictions. using GPUs rather than CPUs offers performance blessings on extremely parallelizable computation.
Hyperparameters
In machine learning, models are trained to predict unknown labels for new data based on correlations between known labels and features found in the training data. Depending on the algorithm used, you may need to specify hyperparameters to configure how the model is trained.
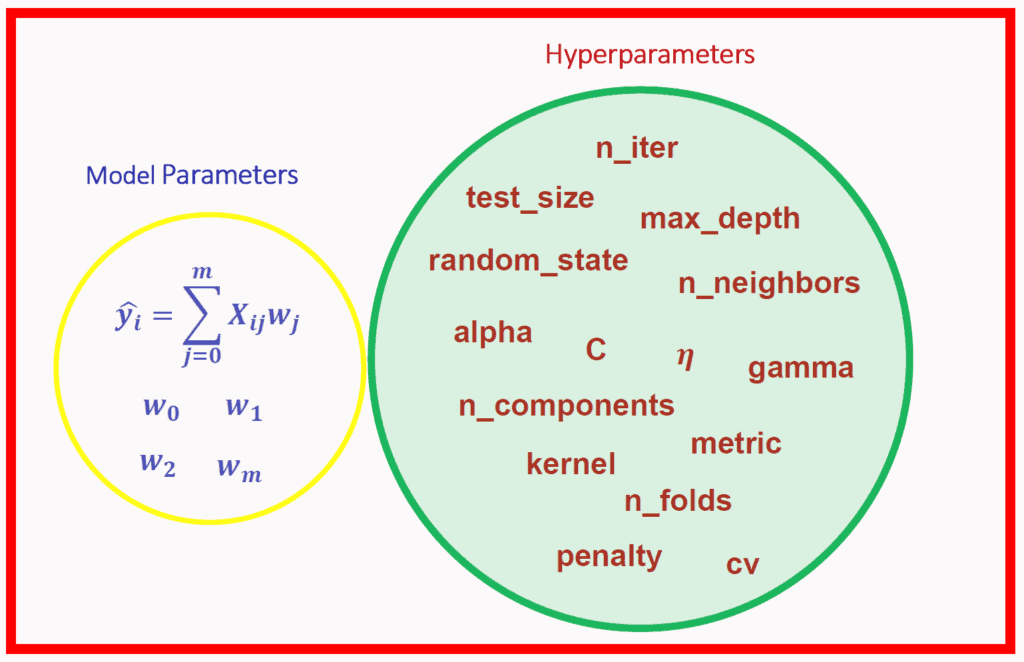
Q5: What are Hyperparameters?
A: A Hyperparameter could be a parameter whose worth is about before the learning method begins. It determines however a network is trained and also the structure of the network (such because the variety of hidden units, the educational rate, epochs, etc.).
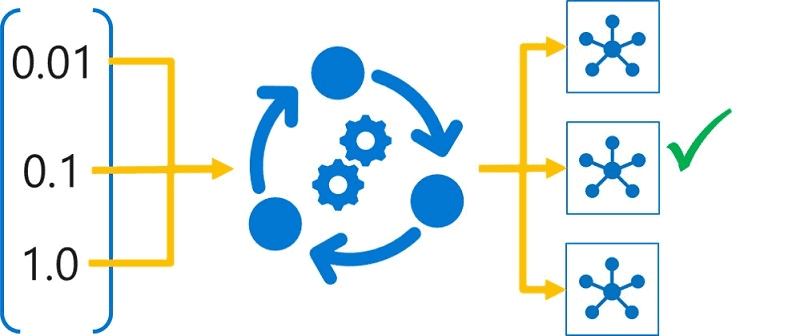
Q6: What are the methods of Hyperparameter Optimization? A: The parameters, called hyperparameters, that define the performance of the machine learning algorithm (model), depends on the problem we are trying to solve. Thus, they need to be configured accordingly. This process of finding the best set of parameters is called hyperparameter optimization. For example, in support vector machines (SVM), the regularization constant, kernel coefficient needs to be optimized. The tuning of optimal hyperparameters can be done in a number of ways.
Grid Search
Random Search
Bayesian optimization
Gradient-based optimization
Evolutionary optimization
Q7: What is hyperparameter tuning in machine learning?
A: Hyperparameter tuning is that the method of finding the configuration of hyperparameters that will lead to the most effective performance. the method is computationally costly and loads of manual work has got to be done. it’s accomplished by coaching the multiple models, victimisation an equivalent formula and coaching knowledge however totally different hyperparameter values. The ensuing model from every coaching run is then evaluated to work out the performance metric that you wish to optimize (for example, accuracy), and also the best-performing model is chosen.
Q8: What is Search Space in Hyperparameter Tuning?
A: The set of hyperparameter values tried throughout hyperparameter standardization is thought of because of the search house. The definition of the vary of doable values which will be chosen depends on the sort of hyperparameter. Hyperparameters will be separate or continuous and have a distribution of values delineated by a parameter expression.
Q9: What is Automated Machine Learning data?
A: Multiple ways in which to specify training and validation data Training data :
Tabular data as well as feature and label
Validation data: optional table for model validation
X and Y: separate feature and label values
X_valid and Y_valid: features and labels for model validation
Q10: What is feature engineering?
A: Feature engineering is that the method of using domain data of the info to make options that facilitate millilitre algorithms learn higher. In Azure Machine Learning, scaling and normalization techniques are applied to facilitate feature engineering. together, these techniques and have engineering are mentioned as featurization.
Q11: What is a confusion matrix?
A:Confusion matrices offer a visible way a machine learning model is creating systematic errors in its predictions for classification models. A Confusion matrix is an N x N matrix used for evaluating the performance of a classification model, wherever N is that the variety of target categories. The matrix compares the particular target values with those foretold by the machine learning model. this provides us with a holistic read of however well our classification model is acting and what types of errors it’s creating.
Q12: Explain Accuracy precision and recall?
A: Accuracy – Accuracy is that the most intuitive performance live and it’s merely a quantitative relation of properly predicted observation to the entire observations. One might imagine that, if we’ve high accuracy then our model is best. Yes, accuracy could be a nice live however only if you have got symmetric datasets wherever values of false positives and false negatives are nearly equivalent. Therefore, you have got to seem at alternative parameters to judge the performance of your model. For our model, we’ve got 0.803 which suggests our model is approx. 80% accurate.
Accuracy = TP+TN/TP+FP+FN+TN
Precision– precision is that the magnitude relation of properly predicted positive observations to the entire predicted positive observations. The question that this metric answer is of all passengers that labelled as survived, what percentage really survived? High precision relates to the low false-positive rate. we’ve got 0.788 exactness that is pretty sensible.
Precision = TP/TP+FP
Recall (Sensitivity) – Recall is that the magnitude relation of properly foretold positive observations to all observations in the actual category – affirmative. The question recall answers are: Of all the passengers that actually survived, what percentage did we have a tendency to label? we’ve got a recall of 0.631 which is nice for this model as it’s on top of 0.5.
Recall = TP/TP+FN
Feedback Received…
From our DP-100 day 5 session, we received some good feedback from our trainees who had attended the session, so here is a sneak peek of it.
Quiz Time (Sample Exam Questions)!
With our AI/ML & Azure Data Science training program, we cover 150+ sample exam questions to help you prepare for the certification DP-100.
Check out one of the questions and see if you can crack this…
Ques: You have a real-time inference web service that you have just deployed to Azure Kubernetes Service. During its run, some unexpected errors occur. You need to troubleshoot it quickly and cost-effectively. Which is the quickest and cheapest option you can use?
A. Deploy it as a local web service and debug locally B. Deploy it to ACI C. Use a compute instance as a deployment target for debugging D. Deploy it to AKS and set the maximum number of replicas to one; debug it in the production environment
Comment with your answer & we will tell you if you are correct or not!!
Begin your journey toward Mastering Azure Cloud and landing high-paying jobs. Just click on the register now button on the below image to register for a Free Class on Mastering Azure Cloud: How to Build In-Demand Skills and Land High-Paying Jobs. This class will help you understand better, so you can choose the right career path and get a higher paying job.
I started my IT career in 2000 as an Oracle DBA/Apps DBA. The first few years were tough (<$100/month), with very little growth.
In 2004, I moved to the UK. After working really hard, I landed a job that paid me £2700 per month.
In February 2005, I saw a job that was £450 per day, which was nearly 4 times of my then salary.





![Microsoft Agentic AI Business Solutions Architect [AB-100] | K21 Academy](https://test.k21academy.com/wp-content/uploads/2025/11/Microsoft-Agentic-AI-Business-Solutions-Architect-AB-100-Exam-Overview1.png)


