




![]()
In this blog, we are going to cover Data, types of Data, and Structured Vs Unstructured Data, and Semi Structured Data.
We store structured data in a predefined format, such as a table, because it is highly specific and easy to organize and analyze. Unstructured data is a compilation of many varied types of data stored in their native formats, such as text, audio, and video, which makes it more difficult to organize and analyze
Here is a table comparing the two types of data:
| Feature | Structured data | Unstructured data |
|---|---|---|
| Format | Predefined | Native |
| Organization | Easy | Difficult |
| Analysis | Easy | Difficult |
| Examples | Tables, spreadsheets, databases | Text, audio, video, images |
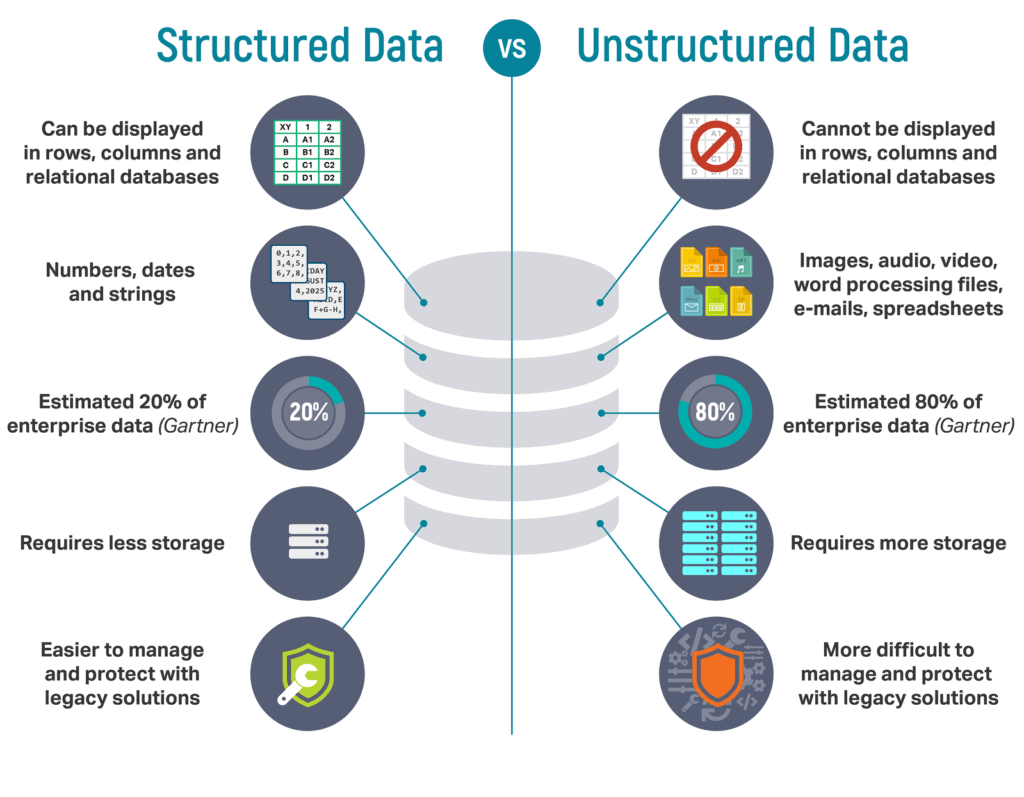
What Is Data?
- Data is a set of facts such as descriptions, observations, and numbers used in decision-making.
- We can classify data as structured, unstructured, or semi-structured data.

1) What is structured data?
- Structured data is generally tabular data that is represented by columns and rows in a database.
- Databases that hold tables in this form are called relational databases.
- The mathematical term “relation” specifies a formed set of data held as a table.
- In structured data, all row in a table has the same set of columns.
- SQL (Structured Query Language) programming language used for structured data.
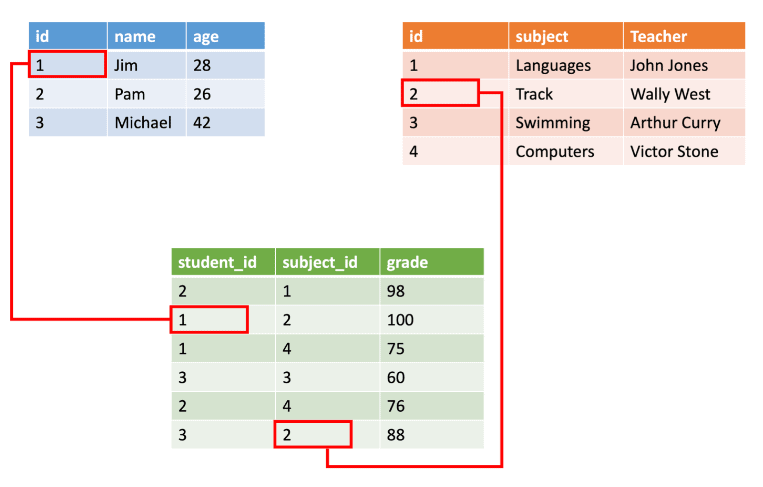
2) What is Semi-structured Data
- Semi-structured data is information that doesn’t consist of Structured data (relational database) but still has some structure to it.
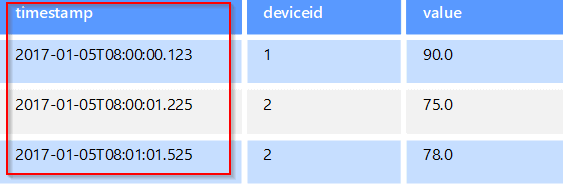
- Semi-structured data consists of documents held in JavaScript Object Notation (JSON) format. It also includes key-value stores and graph databases.

Read: Microsoft DP-900 Exam questions and answers
3) What is Unstructured Data
- Unstructured data is information that either is not organized in a pre-defined manner or does not have a pre-defined data model.
- Unstructured information is a set of text-heavy but may contain data such as numbers, dates, and facts as well.
- Videos, audio, and binary data files might not have a specific structure. They’re assigned to unstructured data.
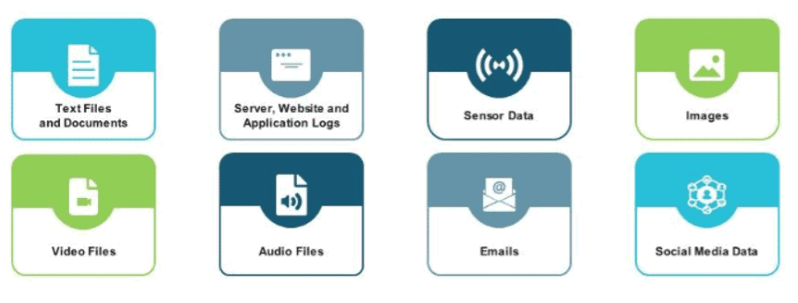
Approaches to storing and managing data
Schema-on-write and schema-on-read are two different approaches to storing and managing data. Schema-on-write means that the schema, or structure, of the data, is defined when the data is written to the database. Schema-on-read means that the schema is defined when the data is read from the database.
Structured data is typically stored using schema-on-write. This is because the schema is known in advance and can be used to optimize the storage and performance of the data. Unstructured data is typically stored using schema-on-read. This is because the schema is not known in advance and may need to be changed frequently.
Which approach is best for a particular application depends on the specific needs of the application.
Structured Data vs Unstructured Data vs Semi-Structured:
Structured data is stored in a predefined format and is highly specific; whereas unstructured data is a collection of many varied data types that are stored in their native formats; while semi-structured data does not follow the tabular data structure models associated with relational databases or other data table forms.
Pros and Cons of Structured Data
| Pros | Cons |
| Requires less processing in comparison to unstructured data and is easier to manage. | Limited usability because of its pre-defined structure/format |
| Machine algorithms can easily crawl and use structured data which simplifies querying | Structured data is stored in data warehouses which are built for space saving but are difficult to change and not very scalable/flexible. |
| As an older format of data, there are several tools available for structured data that simplify usage, management, and analysis |
Pros and Cons of Unstructured Data
| Pros | Cons |
| A variety of native formats facilitates a greater number of use cases and applications | The greater number of formats makes it equally challenging to analyze and leverage unstructured data. |
| As there is no need to predefine data, unstructured data is collected quickly and easily. | The large volume and undefined formats make data management a challenge and specialized tools a necessity. |
| Unstructured data is stored in on-premises or cloud data lakes which are highly scalable. | |
| Although challenging, the greater volume of unstructured data provides better insights and more opportunities to turn your data into a competitive advantage. |
Read: Relational And Non-Relational Datastores
Use cases for Structured data
Examples of structured data include names, dates, addresses, credit card numbers, stock information, geolocation, and more.
Structured data is highly organized and easily understood by machine language. Those working within relational databases can input, search, and manipulate structured data relatively quickly using a relational database management system (RDBMS).
Also Read: Introduction Big Data
Use cases for Semi-Structured data
The use of semi-structured data enables us to integrate data from various sources or exchange data between different systems. Applications and systems need to evolve with time, but if we work purely with structured data, this is not possible. Let’s consider web forms. You may want to modify forms and capture different data for different users. If you are using a traditional relational database, the database schema needs to be changed each time a new field is needed, and fields can not be left empty. Semi-structured data can allow you to capture any data in any structure without making changes to the database schema or coding. Adding or removing data does not impact functionality or dependencies.
Use cases for unstructured data
Here are a few examples where unstructured data is being used in analytics today.
Classifying image and sound. Using deep learning, a system can be trained to recognize images and sounds. The systems learn from labeled examples in order to accurately classify new images or sounds.
As input to predictive models. Text analytics — using natural language processing (NLP) or machine learning — is being used to structure unstructured text.
Chatbots in customer experience. Chatbots have been in the market for a number of years, but the newer ones have a better understanding of language and are more interactive.
Characteristics Of Structured (Relational) and Unstructured (Non-Relational) Data
Relational Data
- Relational databases provide undoubtedly the most well-understood model for holding data.
- The simplest structure of columns and tables makes them very easy to use initially, but the inflexible structure can cause some problems.
- We can communicate with relational databases using Structured Query Language (SQL).
- SQL allows the joining of tables using a few lines of code, with a structure most beginner employees can learn very fast.
- Examples of relational databases:
- MySQL
- PostgreSQL
- Db2

Non-Relational Data
- Non-relational databases permit us to store data in a format that more closely meets the original structure.
- A non-relational database is a database that does not use the tabular schema of columns and rows found in most traditional database systems.
- It uses a storage model that is enhanced for the specific requirements of the type of data being stored.
- In a non-relational database the data may be stored as JSON documents, as simple key/value pairs, or as a graph consisting of edges and vertices.
- Examples of non-relational databases:
- Redis
- JanusGraph
- MongoDB
- RabbitMQ

Read: Azure Cosmos DB – Introduction, Features & Benefits
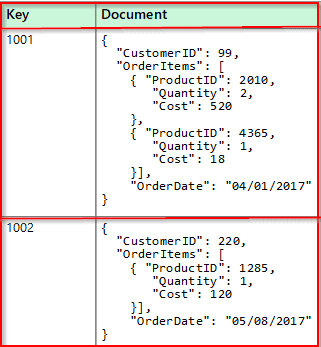
Document Data Stores
- A document data store handles a set of objects data values and named string fields in an entity referred to as a document.
- These data stores generally store data in the form of JSON documents.
Columnar Data Stores
- A columnar or column-family data store constructs data into rows and columns. The columns are divided into groups known as column families.
- Each column family consists of a set of columns that are logically related and are generally retrieved or manipulated as a unit.
- Within a column family, rows can be sparse, and new columns can be added dynamically.

Read More: Power BI Transform Data: Clean and Load Data in Power Query 2022
Key/Value Data Stores
- A key/value store is actually a large hash table.
- We associate each data value with a unique key, and the key/value store uses this key to store the data by using a correct hashing function.
- The hashing function is preferred to provide an even distribution of hashed keys across the data storage.
- Key/value stores are highly suitable for applications operating simple lookups using the value of the by a range of keys.
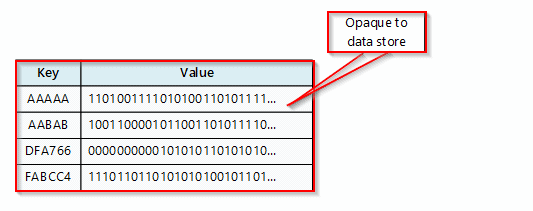
Graph Data Stores
- A graph data store handles two types of information, edges, and nodes.
- Edges point out the relationships between these entities and Nodes represent entities.
- The aim of a graph datastore is to grant an application to efficiently perform queries that traverse the network of edges and nodes and to inspect the relationships between entities.
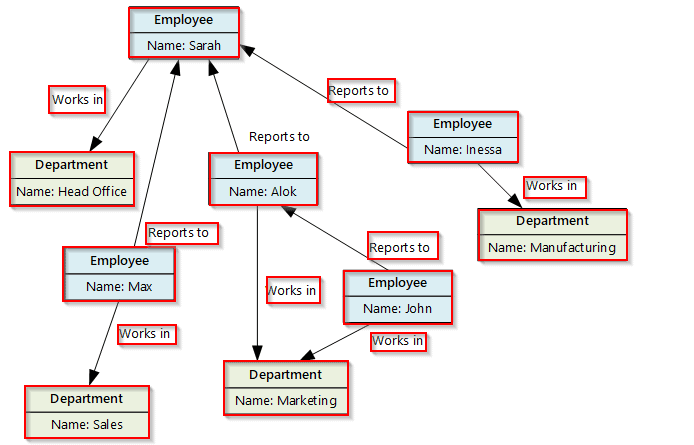
Time series data stores
- Time series data is a set of values formed by time, and a time-series data store is the best for this type of data.
- Time series data stores must support a very large number of writes, as they generally collect large amounts of data in real time from a huge number of sources.
Object data stores
- Object data stores are correct for retrieving and storing large binary objects or blobs such as audio and video streams, images, text files, large application documents and data objects, and virtual machine disk images.
- An object consists of some metadata, stored data, and a unique ID for access to the object.

External index data stores
- External index data stores give the ability to search for information held in other data services and stores.
- An external index acts as a secondary index for any data store. It can provide real-time access to indexes and can be used to index massive volumes of data.
Read about Azure Cosmos DB, Key features and Capabilities, create a Cosmos DB account, and create a database and container.
What are the differences between Structured and Unstructured data?
1) Defined Vs Undefined Data
- Structured data is undoubtedly a defined type of data in a structure.
- Structured data lives in columns and rows and it can be mapped into pre-defined fields.
- Unstructured data does not have a predefined data format, it is a collection of many types of varied data that are stored in their native formats.
2)Quantitative vs. Qualitative Data
- Structured data is generally quantitative data, it usually consists of hard numbers or things that can be counted.
- Methods for analysis include classification, regression, and clustering of data.
- Unstructured data is generally categorized as qualitative data, and cannot be analyzed and processed using conventional tools and methods.
- Understanding qualitative data requires advanced analytics techniques like data stacking and data mining.
3) Storage In Data Lakes vs. Data Houses
- Structured data is generally stored in data warehouses.
- Unstructured data is stored in data lakes.
- Unstructured data requires more storage space, while structured data requires less storage space.
4) Ease Of Analysis
- Structured data is easy to search, both for algorithms and for humans.
- Unstructured data is more difficult to search and requires processing to become understandable.
Structured Vs. Unstructured Data: Next-Gen Tools Are Game Changers
- There are new google’s structured data tools accessible to examine unstructured data, In the main given specified use case parameters. Most of these tools depend on machine learning.
- Machine learning can also be used for structured markup analytics, but it is required for huge amounts and many different types of unstructured data.
- Unstructured data has increased so dramatically that users need to hire analytics that are both fast and can learn from the company’s and users’ resolutions.
Related/References
- Microsoft Certified Azure Data Engineer Associate | DP 203 | Step By Step Activity Guides (Hands-On Labs)
- Exam DP-203: Data Engineering on Microsoft Azure
- Azure Data Lake For Beginners: All You Need To Know
- Introduction to Big Data and Big Data Architectures
- Azure Data Science And Data Engineering Certifications: DP-900 vs DP-100 vs DP-200/DP-201
- Azure Fundamental Certification For Beginners: AZ-900 vs AI-900 vs DP-900
- [AZ-104] Roles And Responsibilities Of A Microsoft Azure Administrator
- Azure Trial Account | Steps to Register for Microsoft Azure Free Account
- Power BI Transform Data: Clean and Load Data in Power Query 2022
Next Task For You
In our Azure Data Engineer training program, we cover 17 Hands-On Labs. If you want to begin your journey towards becoming a Microsoft Certified: Azure Data Engineer Associate check out our FREE CLASS.![[DP.200.201]_CU](https://k21academy.com/wp-content/uploads/2020/10/DP.200.201_CU.gif)
![Microsoft Agentic AI Business Solutions Architect [AB-100] | K21 Academy](https://test.k21academy.com/wp-content/uploads/2025/11/Microsoft-Agentic-AI-Business-Solutions-Architect-AB-100-Exam-Overview1.png)



