



![]()
Ever caught yourself wishing your AI assistant could actually see what you’re pointing at? You’re not alone. 78% of users report frustration when voice assistants can’t understand visual context.
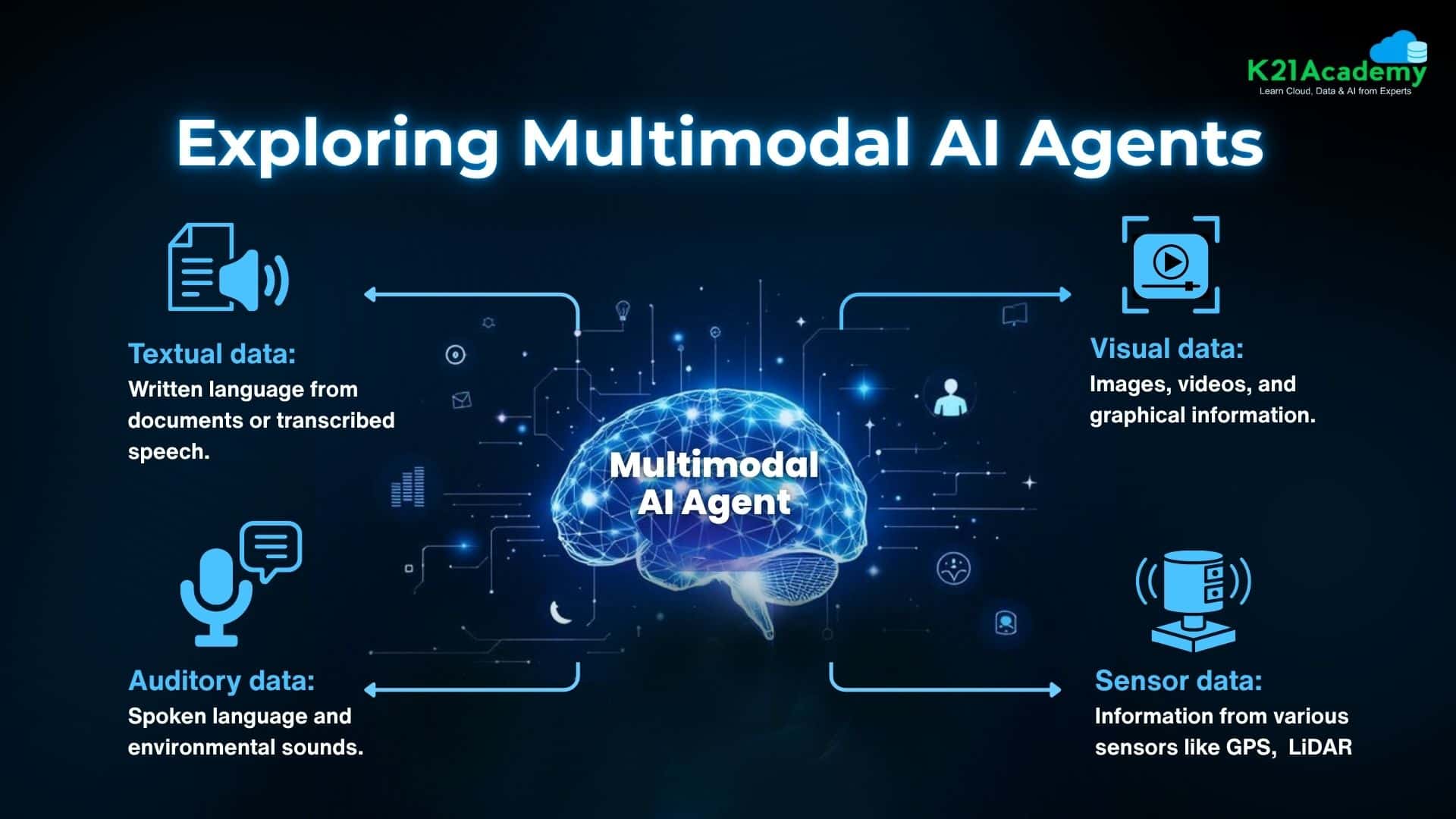
Multimodal AI agents are changing all that. They can see, hear, and understand the world like we do – processing images, text, and speech simultaneously to deliver what feels like actual comprehension. As artificial intelligence keeps getting better, it’s no longer limited to just text or speech. Today’s advanced AI agents can understand and work with multiple types of data—like text, images, audio, and even videos—all at once. These are called multimodal AI agents, and they’re changing the way machines interact with the world around them.
In this blog, we’ll break down what multimodal AI agents really are, how they enhance today’s smart systems, and why businesses are eager to use them. Whether you’re just curious about AI or someone looking to explore its real-world impact, this guide will give you a clear and simple look at the future of intelligent systems.
Table of Contents:
- What are multimodal AI Agents?
- How do multimodal AI Agents enhance AI systems?
- How multimodal AI Agents work?
- Key Benefits of Multimodal AI Agents in Business
- Applications of Multimodal AI Agents
- The Future of Multimodal AI Agents in Industry
- Challenges in Developing Multimodal AI Agents
- Conclusion

What Are Multimodal AI Agents?
Multimodal AI agents are AI systems that can process, understand, and generate outputs using multiple forms of data—such as text, audio, images, video, and sensory data—simultaneously.
Think of them as AI with multiple “senses”. Just like humans use sight, sound, and language together to make sense of the world, multimodal AI combines different inputs to form a richer, more complete understanding. For example:
- A virtual assistant that can see (via a webcam), hear (via a microphone), and read text (from documents).
- A retail chatbot that understands spoken requests, product images, and customer preferences all at once.
Multimodal AI agents are powered by advanced neural networks, often leveraging transformers and foundation models like OpenAI’s GPT-4o, Google’s Gemini, or Meta’s ImageBind—models trained on vast multimodal datasets.
Related Readings: What is Generative AI?
What makes AI agents “multimodal”

Think about how you experience the world—you see, hear, touch, and read all at once. That’s what makes AI agents “multimodal”. Multiple forms of information can be processed and understood simultaneously by these systems.
One kind of data was handled at a time by traditional AI. Text-only. Image-only. Audio-only! Limited and dull, huh?
These barriers are broken by multimodal AI agents. To develop a far more comprehensive awareness of their surroundings, they integrate vision, language, music, and occasionally even tactile feedback.
Consider contemporary virtual assistants. They can see your gestures, interpret the context of your request from what’s on your screen, and answer with the ideal combination of text, graphics, and voice in addition to hearing your command.
Related Readings: Generative AI (GenAI) vs Traditional AI
How Do Multimodal AI Agents Enhance AI Systems?

Traditional AI systems sometimes work in silos, focusing on only one input type—such as processing text exclusively or analysing photos exclusively. This limits their ability to interpret complex real-world situations.
Multimodal agents solve this by:
- Fusing multiple data streams to create deeper context.
- Coordinating actions based on diverse inputs (e.g., adjusting speech tone based on visual emotion cues).
- Responding in multiple formats, like generating a graph from a spoken request or summarising a video.
Related Readings: Top 10 No-Code AI Tools in 2025
Core Technologies Powering Multimodal AI Agents
Computer Vision Components
Have you ever wondered how AI entities “see” the world? Here, computer vision is the answer. These systems break down images into patterns and features using convolutional neural networks (CNNs), which function similarly to our visual cortex.
Modern multimodal agents use vision transformers (ViTs) that can process entire images at once, catching relationships between distant elements in a scene. They don’t just recognise objects—they understand context.
Natural language processing integration
NLP components are the language centres of multimodal AI brains. From basic word matching, they have advanced significantly. GPT-4 and other large language models are now able to comprehend cultural references, irony, and nuance. These models can reason about what they perceive and provide a human-like explanation when paired with vision.
Both parties benefit from the integration: visual input gives verbal comprehension context, while text can direct visual attention (“find the keys on the counter”).
Audio and speech recognition systems
Multimodal AI’s ears are capable of understanding as well as listening. Transformer topologies are used in modern voice recognition to translate sound waves into text with an accuracy of about 95% under ideal circumstances. Raw transcription, however, is only the first step. Additionally, these systems recognise:
- Speaking person (speaker diarisation)
- Sentiment analysis of the emotional tone
- The meaning of background noises
Multimodal AI’s audio processing extends beyond speech. Agents can comprehend context such as traffic noise, appliance sounds, or music playing by using environmental sound recognition.
Multimodal agents can comprehend a wide range of languages and accents because of Whisper and other sophisticated speech models.
Similarly there are other technologies like Tactile and sensor data processing, Cross-modal reasoning architectures, etc.
How Multimodal AI Agents Work

Multimodal AI agents typically consist of:
- Modality-specific encoders (e.g., text encoders, vision encoders)
- A fusion layer that integrates representations from different modalities
- A decision or output generator (e.g., text generator, action planner)
Some agents use transformer-based backbones (like GPT-4, Gemini, or Claude) that are inherently multimodal, enabling seamless cross-modal understanding.
Related Readings: How to Create an AI Agent: Step-by-Step Guide 2025
Key Benefits of Multimodal AI Agents in Business
Key benefits of multimodal AI agents include:
- Richer Context = Better Decisions: Multimodal agents understand situations more holistically, leading to smarter recommendations, insights, and actions.
- Improved Customer Experience: Businesses can offer more personalized and intuitive interactions—whether it’s helping a customer via voice and visuals or auto-generating personalized content.
- Automation of Complex Tasks: Tasks that used to require human intervention—like checking compliance across video and document formats—can now be automated.
- Faster Response Times: Multimodal understanding cuts down on the back-and-forth often needed in unimodal systems. One intelligent input can drive fast, accurate outputs.
- Accessibility and Inclusivity: By understanding sign language (video), spoken queries (audio), and typed input (text), multimodal agents can serve a wider audience, including differently abled users.
Applications of Multimodal AI Agents
Multimodal AI agents aren’t just a lab experiment—they’re already transforming industries. The potential of multimodal agents is immense. Here’s how they’re expected to reshape industries:
- In healthcare, they merge medical imaging with patient histories to suggest more accurate diagnoses.
- In retail, they power visual search engines that turn a product photo into tailored recommendations.
- Education is seeing AI tutors that can break down complex diagrams into simple explanations.
- While customer service teams use agents that interpret screenshots to solve issues faster.
- Even autonomous vehicles rely on multimodal AI, fusing camera feeds, LIDAR data, and maps to make split-second driving decisions.
By integrating text, image, and knowledge, these agents bridge the gap between human-like understanding and machine efficiency—bringing AI closer to everyday life than ever before.
Related Readings: Generative AI Use Cases in Healthcare, Finance & Education
The Future of Multimodal AI Agents in Industry
As foundation models become more powerful, multimodal agents will evolve into general-purpose assistants that can:
- Watch videos and generate summaries
- Read documents and explain visuals
- Understand emotional tone from voice + face
- Make real-time decisions based on sensory data
When vision (seeing), cognition (thinking), and knowledge (reasoning) are combined, autonomous, intelligent agents that can function in real-world settings with little assistance from humans will emerge.
Challenges in Developing Multimodal AI Agents
While exciting, multimodal AI still comes with challenges:
- Data Alignment & Integration: Syncing data across formats (e.g., matching text with video timestamps) can be technically complex.
- High Computational Costs: Training and running multimodal models demand massive compute resources and storage.
- Bias and Ethical Risks: Multimodal models may reinforce visual, audio, or text biases—making fair data representation critical.
- Security & Privacy Concerns: Processing sensitive audio, video, or images raises new risks around consent, misuse, and surveillance.
- Lack of Standardization: Different companies use different models, formats, and evaluation benchmarks—slowing interoperability and adoption.
Overcoming these hurdles will require innovation in model architecture, responsible AI policies, and collaborative ecosystem building.
Conclusion
A major advancement in artificial intelligence is represented by multimodal AI agents, which combine text, image, voice, and video processing to provide more adaptable and human-like systems. Multimodal AI agents are pushing the boundaries of what AI can do. By learning from and interacting with the world through multiple senses—text, visuals, audio, and more—they offer richer insights, better decisions, and more human-like experiences.
From smart customer service to next-gen healthcare and autonomous operations, the applications are already reshaping industries. And while challenges remain, the path forward is clear: the future of smart systems is multimodal.
Whether you’re a business leader, a developer, or simply AI-curious, now is the time to explore how these intelligent agents can bring your systems to life.
Frequently Asked Questions
What is the difference between multimodal models & foundation models?
Foundation models are capable of understanding multiple inputs, whereas multimodal agents use them to perform actions based on goals.
What is a multimodal AI?
Multimodal AI is a type of artificial intelligence that can understand and process different types of information, such as text, images, audio, and video, all at the same time.
What is the difference between generative AI and multimodal AI?
Certain generative artificial intelligence (AI) systems generate text as their output and only accept one kind of input, like text. Other AI systems can generate a variety of outputs and receive a variety of inputs, including text and graphics. We refer to these as multimodal AI systems.
Is ChatGPT multimodal?
Yes, ChatGPT is multimodal. It can process and understand various forms of input, including text, images, and audio, within the same conversation or prompt.
What are the five languages of multimodality?
In the composition field, multimodal elements are commonly defined in terms of the five modes of communication: linguistic, visual, gestural, spatial, audio.
![Microsoft Agentic AI Business Solutions Architect [AB-100] | K21 Academy](https://test.k21academy.com/wp-content/uploads/2025/11/Microsoft-Agentic-AI-Business-Solutions-Architect-AB-100-Exam-Overview1.png)



