




![]()
In this blog, we are going to discuss the assorted ways in which to envision the performance of our machine learning model and why to use one in situ of the other. we are going to discuss terms like:
- Confusion matrix
- Accuracy
- Precision
- Recall/Sensitivity/True Positive Rate
- Specificity
- False Positive Rate
- F1 score
- ROC (Receiver Operating Characteristics) curve
- AUC
- RMSE
- R-squared (R²)
- Performance Metrics in Machine Learning
- Model Evaluation Metrics in Machine Learning
- Evaluating Machine Learning Models
- Model Evaluation Examples
- FAQs
- Conclusion
The goal of a Machine Learning Model is to find out patterns that generalize well on unseen information rather than simply memorizing the information that it had been trained on. once your model is prepared, you’d use it to predict the solution on the analysis or take a look at the data set and then compare the anticipated target to the particular answer (ground truth). this can be a typical approach that’s followed to judge model performance. However, this comparison between foreseen and actual values is performed a supported by a variety of various metrics. the selection of actual metrics depends on the ML drawback at hand.
1. Confusion Matrix
A key concept that we want to understand before having the ability to clarify the performance metrics is the confusion matrix.
Definition: A confusion matrix may be a table that’s usually accustomed to describe the performance of a classification model (or “classifier”) on a group taking a look at data that truth values are well-known.
A confusion matrix can appear as if this:

we will largely discuss things in terms of a binary classification drawback wherever let’s say we’ll have to be compelled to realize if a picture is of a cat or a dog. Or a patient has cancer (positive) or is found healthy (negative). Some common terms to be clear with are:
- True positives (TP): Predicted positive and are positive.
- False positives (FP): Predicted positive and negative.
- True negatives (TN): Predicted negative and are actually negative.
- False negatives (FN): Predicted negative and are actually positive.
Typical metrics for classification issues are Accuracy, Precision, Recall, False positive rate, and F1-measure, and these are derived from the Confusion Matrix. every metric measures a special side of the predictive model.
2. Accuracy
The most ordinarily used metric to gauge a model and is not a transparent indicator of the performance. the more serious happens once categories are unbalanced.

Take for example a cancer detection model. The probability of really having cancer is low. Let’s say out of a hundred, ninety of the patients don’t have cancer and therefore the remaining ten even have it. we tend to don’t wish to miss a patient who has cancer but goes unseen (false negative). detective work everybody as not having cancer offers an accuracy of ninetieth straight. The model did nothing here however simply gave cancer-free for all the hundred predictions.
Check Out: Top Data Science Interview Questions.
3. Precision
Percentage of positive instances out of the total predicted positive instances. Here divisor is that the model prediction is done as positive from the complete given dataset. Take it on resolve ‘how abundant the model is true once it says it’s right’.

4. Recall/Sensitivity/True Positive Rate(TPR)
Percentage of positive instances out of the total actual positive instances. so divisor (TP + FN) here is the actual number of positive instances gift within the dataset. Take it on resolve ‘how much further right ones, the model lost once it showed the correct ones’.

Read More: About Azure DevOps for Data Science.
5. Specificity
Percentage of negative instances out of the total actual negative instances. so divisor (TN + FP) here is the actual number of negative instances of the gift within the dataset. it’s just like recall however the shift is on the negative instances. Like sorting out what percentage of healthy patients didn’t have cancer and were told they didn’t have cancer. reasonably a life to visualize however separate the categories are.

6. False Positive Rate (FPR)
This term offers you the number of false positives (0s predicted as 1s) divided by the entire number of negatives. you’ll be able to see that the formula for False Positive Rate (FPR) is nothing but (1 — Specificity)
7. F1 score
It is the mean value of precision and recall. This takes the contribution of each, therefore the higher the F1 score, the better. See that because of the product within the dividend if one goes low, the ultimate F1 score goes down considerably. therefore a model will do well in the F1 score if the positives predicted are literally positives (precision) and does not miss out on positives and predicts them negatively (recall).

One downside is that each precision and recall are given equal importance because of that consistent with our application we tend to have one on top of the opposite and the F1 score might not be the precise metric for it. so either a weighted F1 score or seeing the PR or mythical creature curve will facilitate.
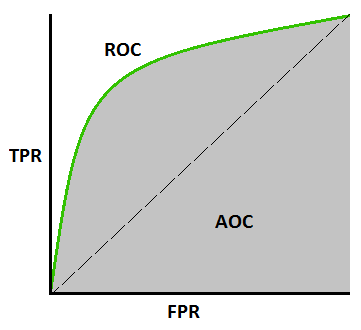
8. ROC Curve
ROC Curves show an exchange between the Truth Positive Rate (TPR or Recall) and therefore the False Positive Rate (FPR). it’s established from the formulas on top that, TPR and FPR are nothing but sensitivity and (1 — specificity), therefore it may be checked out as a trade-off between sensitivity and specificity. The plot between the true positive rate against the false positive rate is thought of because of the mythical creature curve. As you’ll be able to see from the below sample graph, for higher values of TPR, you may even have higher values of FPR, which could not be sensible. therefore it’s all regarding finding a balance between these 2 metrics. a decent mythical creature curve is the one that touches the upper-left corner of the graph; therefore the higher the world underneath the curve(AUC) of a mythical creature curve, the higher your model.

9. AUC (Area under Curve)
AUC may be a completely different sort of metric. It measures the power of the model to predict a better score for positive examples as compared to negative examples. it’s freelance of the chosen threshold, you’ll be able to get away from the prediction performance of your model from the AUC metric while not choosing a threshold. If the roc curve is additional towards the upper-left corner of the graph, it means the model is incredibly sensible.

10. RMSE
Root Mean Square Error (RMSE) is the standard deviation of the residuals (prediction errors). Residuals are a life of however removed from the curve information points are; RMSE may be a measure of however displayed these residuals are. In other words, it tells you ways focused the data is around the line of the best match. Root mean square error is usually utilized in meteorology, foretelling, and regression analysis to verify experimental results
The formula is:
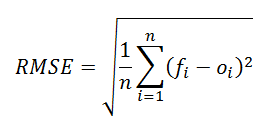 Where:
Where:
- f = forecasts (expected values or unknown results),
- o = observed values (known results).
- n = Total number of observations.
11. R-squared (R²)
R-squared may be applied in math live that represents the proportion of the variance for a variable that’s explained by AN variable or variables in an exceeding regression model. R-squared values vary from zero to one and are ordinarily explicit as percentages from third to 100%. an R-squared of 100% means all movements of a variable are fully explained by movements within the freelance variable(s). it’s conjointly referred to as the Coefficient of Determination.
Where :
- SSE = Residual(Predicted Error) sum of squares
- SST = Total sum of squares
12.Performance Metrics in Machine Learning
Performance metrics in machine learning are crucial for evaluating model effectiveness and guiding improvement. Common metrics like accuracy, precision, recall, and F1 score assess classification models by measuring prediction accuracy and error balance. For regression, metrics such as Mean Absolute Error (MAE), Mean Squared Error (MSE), and Mean Absolute Percentage Error (MAPE) quantify how closely predictions match actual values, highlighting areas for adjustment. Cross-validation and the holdout method are often used to ensure model robustness, providing insights into its generalization on new data. By choosing appropriate metrics, practitioners can refine models for optimized performance in real-world applications.
13.Model Evaluation Metrics in Machine Learning
Model evaluation metrics are essential in machine learning to assess a model’s performance and reliability. Common metrics include accuracy, which measures the percentage of correct predictions, and precision and recall, which are critical in imbalanced datasets, highlighting a model’s specificity and sensitivity. F1-score combines precision and recall for a balanced evaluation, especially in classification tasks. For regression models, metrics like Mean Squared Error (MSE), Mean Absolute Error (MAE), and Mean Absolute Percentage Error (MAPE) gauge prediction accuracy by measuring error magnitude. These metrics enable model tuning, guiding the selection of the most effective model for real-world applications.
14.Evaluating Machine Learning Models
Evaluating machine learning models is essential to ensure their accuracy, reliability, and generalization to new data. Common evaluation metrics vary based on the task: for regression, metrics like Mean Squared Error (MSE), Mean Absolute Error (MAE), and Mean Absolute Percentage Error (MAPE) assess prediction accuracy; for classification, metrics such as accuracy, precision, recall, and F1 score determine performance. Cross-validation techniques, like k-fold and the holdout method, help verify that models perform well across different data samples. Proper evaluation not only improves model quality but also aids in identifying areas for refinement, leading to more robust and effective solutions.
15.Model Evaluation Examples
Model evaluation is crucial in assessing a model’s effectiveness and generalizability. Examples include Mean Squared Error (MSE), which penalizes large errors by squaring them, making it ideal for identifying large deviations. Mean Absolute Error (MAE) provides a straightforward average of errors, reflecting prediction accuracy without amplifying outliers. Mean Absolute Percentage Error (MAPE) normalizes error as a percentage, which is especially useful when comparing models across different datasets. Cross-validation divides data into subsets for training and validation, improving model reliability, while the holdout method splits data once for a quick assessment. Together, these techniques ensure robust and reliable model performance.
16.FAQs
How are precision and recall calculated, and what are their drawbacks?
Precision is calculated as true positives divided by the sum of true and false positives, showing result accuracy. Recall is true positives over true positives plus false negatives, reflecting completeness.
What is the Mean Squared Error (MSE) and why is it important for regression models?
Mean Squared Error (MSE) measures the average squared differences between predicted and actual values in regression models. It’s crucial because it penalizes large errors more heavily, providing a clear indicator of model accuracy and prediction reliability.
What does Mean Absolute Percentage Error (MAPE) signify in model evaluation?
Mean Absolute Percentage Error (MAPE) measures a model's prediction accuracy by averaging the absolute percentage errors between predicted and actual values. It provides insights into model reliability, particularly useful in comparing performance across datasets with different scales.
What is K Fold Cross Validation and how does it work?
K-Fold Cross Validation is a model evaluation technique that splits data into k subsets, or folds. The model is trained on k-1 folds and tested on the remaining fold, rotating until each subset is tested, ensuring reliable performance.
How is Mean Absolute Error (MAE) calculated and interpreted in regression analysis?
Mean Absolute Error (MAE) measures the average magnitude of errors in a regression model without considering direction, calculated as the average of absolute differences between predicted and actual values. Lower MAE indicates better model accuracy.
How does cross-validation differ from the holdout method in model evaluation?
Cross-validation and the holdout method differ in model evaluation by data usage: the holdout method splits data once into training and test sets, while cross-validation repeatedly partitions data into multiple subsets, providing a more robust performance estimate.
How can one build and evaluate a simple regression model using Python?
To build and evaluate a simple regression model in Python, import essential libraries like scikit-learn, split your data, fit a model (e.g., Linear Regression), and evaluate it using metrics like Mean Squared Error (MSE) or R-squared for accuracy.
How can Python libraries like Pandas, Numpy, Matplotlib, Seaborn, and Sklearn assist in model evaluation?
Python libraries like Pandas, Numpy, Matplotlib, Seaborn, and Sklearn are essential for model evaluation. Pandas and Numpy handle data manipulation, while Matplotlib and Seaborn visualize performance metrics, and Sklearn provides evaluation metrics like accuracy and MSE for insights.
17.Conclusion
In conclusion, evaluating a machine learning model’s performance is crucial for understanding its accuracy, reliability, and practical applicability. By assessing metrics such as accuracy, precision, recall, F1 score, and error rates, you can ensure the model meets desired outcomes and effectively generalizes to new data, supporting informed decisions in real-world scenarios.
Related/References
- oin Our Generative AI Whatsapp Community
- Azure AI/ML Certifications: Everything You Need to Know
- Azure GenAI/ML : Step-by-Step Activity Guide (Hands-on Lab) & Project Work
- DP 100 Exam | Microsoft Certified Azure Data Scientist Associate
- Step By Step Activity Guides (Hands-On Labs) for DP-100 certification
- Microsoft Azure AI Fundamentals – AI-900 Exam Detailed Overview
- Microsoft Azure Data Scientist DP-100 FAQ
- [DP-100] Design & Implement a Data Science Solution on Azure Question & Answers/Day 1 Live Session Review
Next Task: Enhance Your Azure AI/ML Skills

![Microsoft Agentic AI Business Solutions Architect [AB-100] | K21 Academy](https://test.k21academy.com/wp-content/uploads/2025/11/Microsoft-Agentic-AI-Business-Solutions-Architect-AB-100-Exam-Overview1.png)



