




![]()
This blog covers Azure Synapse Analytics used for big data analytics and compares some SQL technologies like Azure Synapse SQL Vs Apache Spark and Dedicated SQL Vs Serverless SQL with the following topics covered.
- Azure Synapse Analytics
- What Is Azure Synapse SQL?
- What Is Apache Spark?
- Synapse SQL Vs Apache Spark
- Dedicated SQL Vs Serverless SQL
- Conclusion
Azure Synapse Analytics
Azure Synapse Analytics is an analytics service that helps in data integration, data warehousing, and big data analytics. Azure Synapse gives a unified experience to ingest, explore, prepare, manage, and serve data for immediate BI (Business Intelligence) and machine learning needs. It gives the freedom to query data using either serverless or dedicated resources.

Key Features Of Azure Synapse Analytics
- Unified Analytics Platform
- Enterprise Data Warehousing
- Data Lake Exploration
- Serverless and Dedicated Options
- Code-Free Hybrid Data Integration
- Integrated AI (Artificial Intelligence) and BI (Business Intelligence)
- End-to-End Management and Monitoring
Key Benefits Of Using Azure Synapse Analytics
- It offers data warehousing, machine learning analytics, and dashboarding.
- It uses MPP (Massively Parallel Processing) database technology to process a large amount of data efficiently.
- It helps in querying massive data.
- Easy integration with Azure solutions like Azure Data Lake, Azure Blob Storage, etc.
- Compatible with a wide range of scripting languages like SQL, T-SQL, Spark SQL, Python, Java, .NET, etc.
Also Check: Our blog post on Azure Databricks.
What Is Azure Synapse SQL?
Azure Synapse SQL is a big data analytic service to query and analyze data. It is distributed query system enabling data warehousing and data virtualization. Synapse SQL is based on T-SQL (Transact SQL) for streaming data. It helps in big data analytics and makes use of machine learning solutions. Azure Synapse Analytics provides flexibility to choose between the two consumptions models for Azure Synapse SQL: Dedicated SQL pool and Serverless SQL pool. Before diving into the comparison of Azure Dedicated SQL vs Serverless SQL, let’s discuss some basics of both.
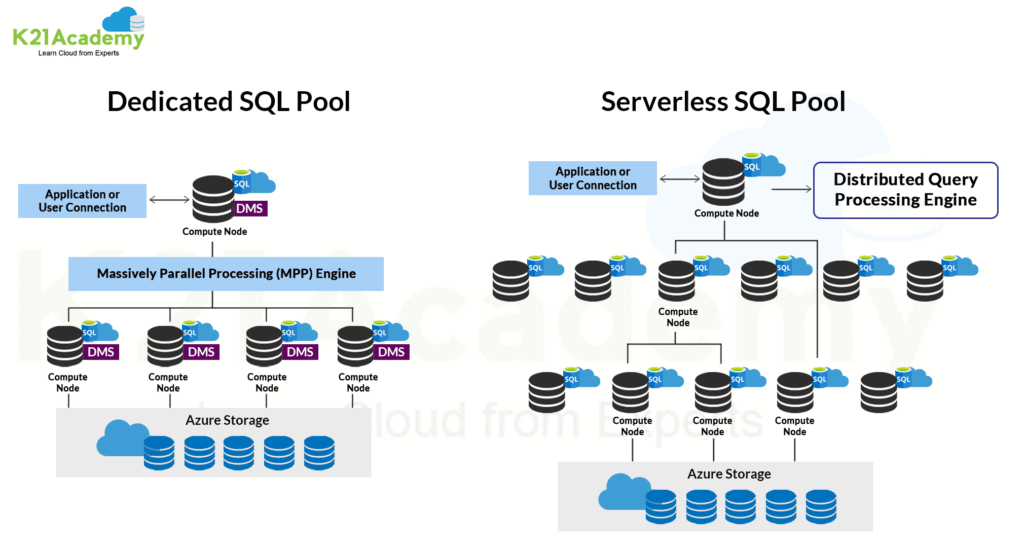
Dedicated SQL Pool
Before coming to the Synapse family, the Dedicated SQL pool was earlier known as Azure SQL Data Warehouse. While using Synapse SQL, a dedicated SQL pool represents a collection of analytic resources that are provisioned. In other words, it is a big data solution that stores data in a relational table with columnar storage. It improves query performance and significantly reduces the storage cost. The size of a dedicated SQL pool is measured in Data Warehousing Units (DWU). After having your data in a Dedicated SQL pool, you can leverage it for analytics at a massive scale.
Serverless SQL Pool
A serverless SQL pool is a distributing data processing system used for storing and computing large-scale data. In the Azure Serverless SQL pool, there is no need to set up infrastructure and maintain clusters. Serverless SQL pool uses a pay-per-use model, so there is no charge for resources reserved, and the charges are made for the data processed by each query that you run.
Also Check: Our blog post on Azure Data Factory Interview Questions.
What Is Apache Spark?
Apache Spark is a database management system used for fast computing using cluster computation. Apache Spark is an open-source industry-standard big data engine used for data preparation, data engineering, ETL (Extract, Transform, Load), and machine learning solutions. It is efficient in streaming big data. In Azure, Apache Spark works as a parallel processing framework that supports in-memory processing to boost the performance of big-data analytic applications. No resources are consumed, running, or charged on a Spark pool creation as it only exists as metadata. Apache spark can auto-scale by adding or removing nodes depending on the need. Before diving into the comparison of Azure Synapse SQL Vs Apache Spark, let’s discuss some components of Apache Spark.
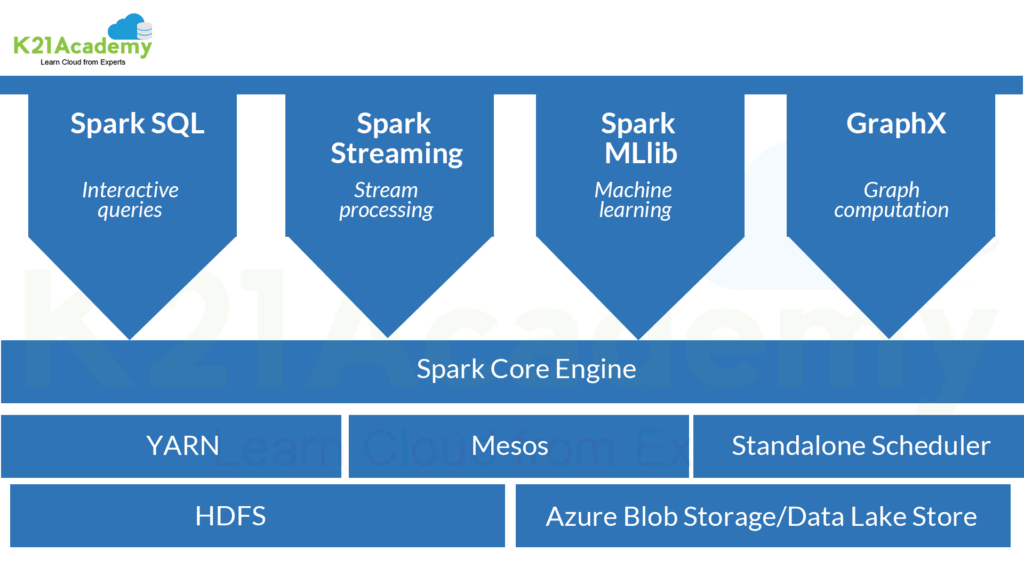
Components Of Apache Spark
- Apache Spark Core – In a spark framework, Spark Core is the base engine for providing support to all the components. It is responsible for in-memory computing.
- Spark SQL – To implement the action, it serves as an instruction. It allows working on the semi-structured and structured data.
- Spark Streaming – With the help of Spark Core, it ingests the data in small batches for producing streaming analytics.
- MLib – Machine Learning Library is a framework that helps in fast processing speed when the computations are performed on the disk.
- GraphX – It is a framework used for producing graphical representations of the computation run by Spark.
Azure Synapse SQL Vs Apache Spark
| Azure Synapse SQL | Apache Spark |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Dedicated SQL Vs Serverless SQL
| Dedicated SQL Pool | Serverless SQL Pool |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Conclusion
Azure Synapse Analytics is a service provided by Microsoft Azure for data warehousing and big data analytics. In Azure, a user can opt for various SQL technologies like Azure Synapse SQL Vs Apache Spark and Dedicated SQL Vs Serverless SQL. Each technology helps a user uniquely with different sets of features. This blog compared some features of each SQL technology used in Azure Synapse Analytics.
Related/References
- Microsoft Azure Data on Cloud Job Oriented Step By Step Activity Guides (Hands-On Labs) & Projects
- Azure Data Lake For Beginners: All you Need To Know
- Batch Processing Vs Stream Processing: All you Need To Know
- Azure Synapse Analytics (Azure SQL Data Warehouse)
- Azure SQL Database | All You Need to Know About Azure SQL Services
Next Task For You
In our Azure Data Engineer training program, we will cover 50 Hands-On Labs. If you want to begin your journey towards becoming a Microsoft Certified: Azure Data Engineer Associate by checking out our FREE CLASS.

![Microsoft Agentic AI Business Solutions Architect [AB-100] | K21 Academy](https://test.k21academy.com/wp-content/uploads/2025/11/Microsoft-Agentic-AI-Business-Solutions-Architect-AB-100-Exam-Overview1.png)



